 Dreamsome
2024.01.09
Dreamsome
2024.01.09

随着 GPTs 的发布,构建私有知识库变得无比简易,这为个人创建数字化身份、第二大脑,或是企业建立知识库,都提供了全新的途径。然而,基于众所周知的原因,GPTs 在中国的使用依然存在诸多困扰和障碍。因此,在当下企业最稳妥的知识库应用方式仍是基于开源 LLM 进行私有化部署,结合向量数据库和提示词规则设计。
Xinference 是一款开源模型推理平台,除了支持 LLM,它还可以部署 Embedding 和 ReRank 模型,这在企业级 RAG 构建中非常关键。同时,Xinference 还提供 Function Calling 等高级功能。还支持分布式部署,也就是说,随着未来应用调用量的增长,它可以进行水平扩展。FastGPT 是一个知识库问答系统,与其他知识库产品相比,FastGPT 能够通过 Flow 进行可视化的工作流编排,实现复杂的问答场景,这对于处理企业级别的复杂场景非常重要。
本文将手把手地教学,用 Xinference 部署一个开源 LLM——Qwen-14B,并借助 FastGPT 的可视化工作流编排,轻松地创建一个能通过查询天气 API 进行对话的聊天应用。
1.安装 Xinference
Xinference 支持多种推理引擎作为后端,以满足不同场景下部署大模型的需要,下面我会分使用场景来介绍一下这三种推理后端,以及他们的使用方法。
1.1 服务器
如果你的目标是在一台 Linux 或者 Window 服务器上部署大模型,可以选择 Transformers 或 vLLM 作为 Xinference 的推理后端:
-
Transformers :通过集成 Huggingface 的 Transformers 库作为后端,Xinference 可以最快地集成当今自然语言处理(NLP)领域的最前沿模型(自然也包括 LLM)。
-
vLLM: vLLM 是由加州大学伯克利分校开发的一个开源库,专为高效服务大型语言模型(LLM)而设计。它引入了 PagedAttention 算法, 通过有效管理注意力键和值来改善内存管理,吞吐量能够达到 Transformers 的 24 倍,因此 vLLM 适合在生产环境中使用,应对高并发的用户访问。
假设你服务器配备 NVIDIA 显卡,可以参考这篇文章中的指令来安装 CUDA,从而让 Xinference 最大限度地利用显卡的加速功能。
1.1.1 Docker 部署
你可以使用 Xinference 官方的 Docker 镜像来一键安装和启动 Xinference 服务(确保你的机器上已经安装了 Docker),命令如下:
docker run -p 9997:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0
1.1.2 PyPi 安装和本地启动
首先我们需要准备一个 3.9 以上的 Python 环境运行来 Xinference,建议先根据 conda 官网文档安装 conda。 然后使用以下命令来创建 3.11 的 Python 环境:
conda create --name py311 python=3.11
conda activate py311
以下两条命令在安装 Xinference 时,将安装 Transformers 和 vLLM 作为 Xinference 的推理引擎后端:
pip install "xinference[transformers]"
pip install "xinference[vllm]"
pip install "xinference[transformers,vllm]" # 同时安装
PyPi 在 安装 Transformers 和 vLLM 时会自动安装 PyTorch,但自动安装的 CUDA 版本可能与你的环境不匹配,此时你可以根据 PyTorch 官网中的安装指南来手动安装。
只需要输入如下命令,就可以在服务上启动 Xinference 服务:
xinference-local -H 0.0.0.0
Xinference 默认会在本地启动服务,端口默认为 9997。因为这里配置了-H 0.0.0.0参数,非本地客户端也可以通过机器的 IP 地址来访问 Xinference 服务。
1.2 个人设备
如果你想在自己的 Macbook 或者个人电脑上部署大模型,推荐安装 CTransformers 作为 Xinference 的推理后端。CTransformers 是用 GGML 实现的 C++ 版本 Transformers。
GGML 是一个能让大语言模型在消费级硬件上运行的 C++ 库。 GGML 最大的特色在于模型量化。量化一个大语言模型其实就是降低权重表示精度的过程,从而减少使用模型所需的资源。 例如,表示一个高精度浮点数(例如 0.0001)比表示一个低精度浮点数(例如 0.1)需要更多空间。由于 LLM 在推理时需要加载到内存中的,因此你需要花费硬盘空间来存储它们,并且在执行期间有足够大的 RAM 来加载它们,GGML 支持许多不同的量化策略,每种策略在效率和性能之间提供不同的权衡。
通过以下命令来安装 CTransformers 作为 Xinference 的推理后端:
pip install xinference
pip install ctransformers
因为 GGML 是一个 C++ 库,Xinference 通过 llama-cpp-python 这个库来实现语言绑定。对于不同的硬件平台,我们需要使用不同的编译参数来安装:
- Apple Metal(MPS):
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python - Nvidia GPU:
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python - AMD GPU:
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
安装后只需要输入 xinference-local,就可以在你的 Mac 上启动 Xinference 服务。
2.部署 Qwen-14B 模型
2.1 Web UI 方式启动模型
Xinference 启动之后,在浏览器中输入: http://localhost:9997,我们可以访问到本地 Xinference 的 Web UI。
打开“Launch Model”标签,搜索到 qwen-chat,选择模型启动的相关参数,然后点击模型卡片左下方的小火箭🚀按钮,就可以部署该模型到 Xinference。 默认 Model UID 是 qwen-chat(后续通过将通过这个 ID 来访问模型)。

当你第一次启动 Qwen 模型时,Xinference 会从 HuggingFace 下载模型参数,大概需要几分钟的时间。Xinference 将模型文件缓存在本地,这样之后启动时就不需要重新下载了。 Xinference 还支持从其他模型站点下载模型文件,例如 modelscope。
2.2 命令行方式启动模型
我们也可以使用 Xinference 的命令行工具来启动模型,默认 Model UID 是 qwen-chat(后续通过将通过这个 ID 来访问模型)。
xinference launch -n qwen-chat -s 14 -f pytorch
除了 WebUI 和命令行工具, Xinference 还提供了 Python SDK 和 RESTful API 等多种交互方式, 更多用法可以参考 Xinference 官方文档。
3. 安装和部署 FastGPT,并接入模型
在上一部分中,我们利用 Xinference 提供的模型服务在本地成功部署了大型语言模型(LLM)——Qwen。接下来,我们安装和部署 FastGPT,并且接入我们刚刚部署好的 Qwen 模型。
FastGPT 使用了 one-api 项目来管理模型池,其可以兼容 OpenAI 、Azure 、国内主流模型和本地模型等。下面先介绍 One API 的安装和使用。
3.1 One API 的安装和配置
One API 是一个 OpenAI 接口管理 & 分发系统,可以通过标准的 OpenAI API 格式访问所有的大模型。 FastGPT 可以通过接入 OneAPI 来实现对不同大模型的支持。
One API 的部署方法也很简单,下面是参考官方项目的 README 用 Docker 命令部署的例子:
docker run --name one-api -d --restart always -p 3001:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api
其中,3001 是宿主机的端口,可以根据需要进行修改。数据和日志将会保存在宿主机的 /home/ubuntu/data/one-api 目录,建议改为合适的目录。
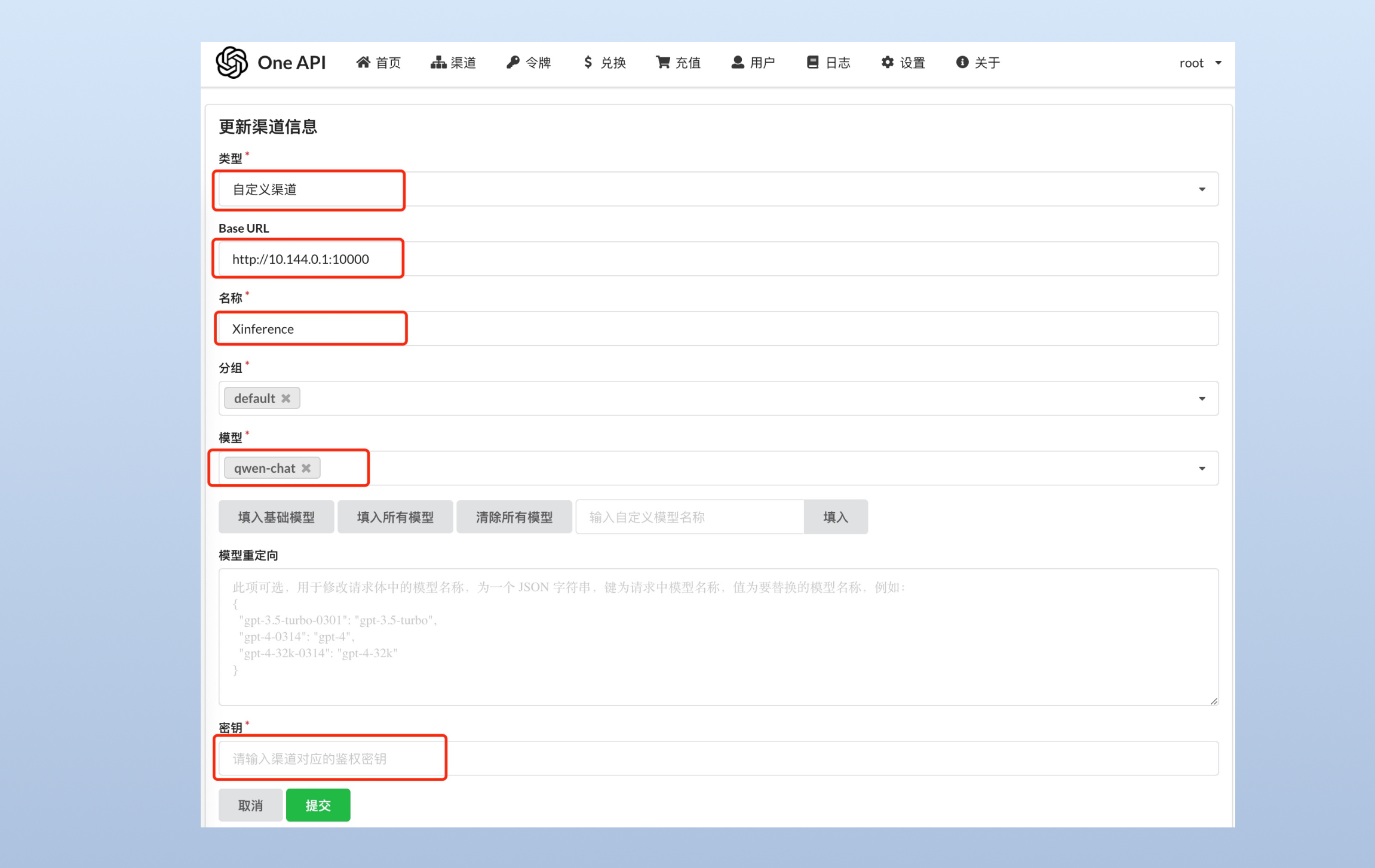
登录 one-api,初始账号用户名为 root,密码为 123456。然后,添加 Xinference 的模型渠道,这里的 Base URL 需要填 Xinference 服务的端点,并且注册 qwen-chat (模型的 UID) 。
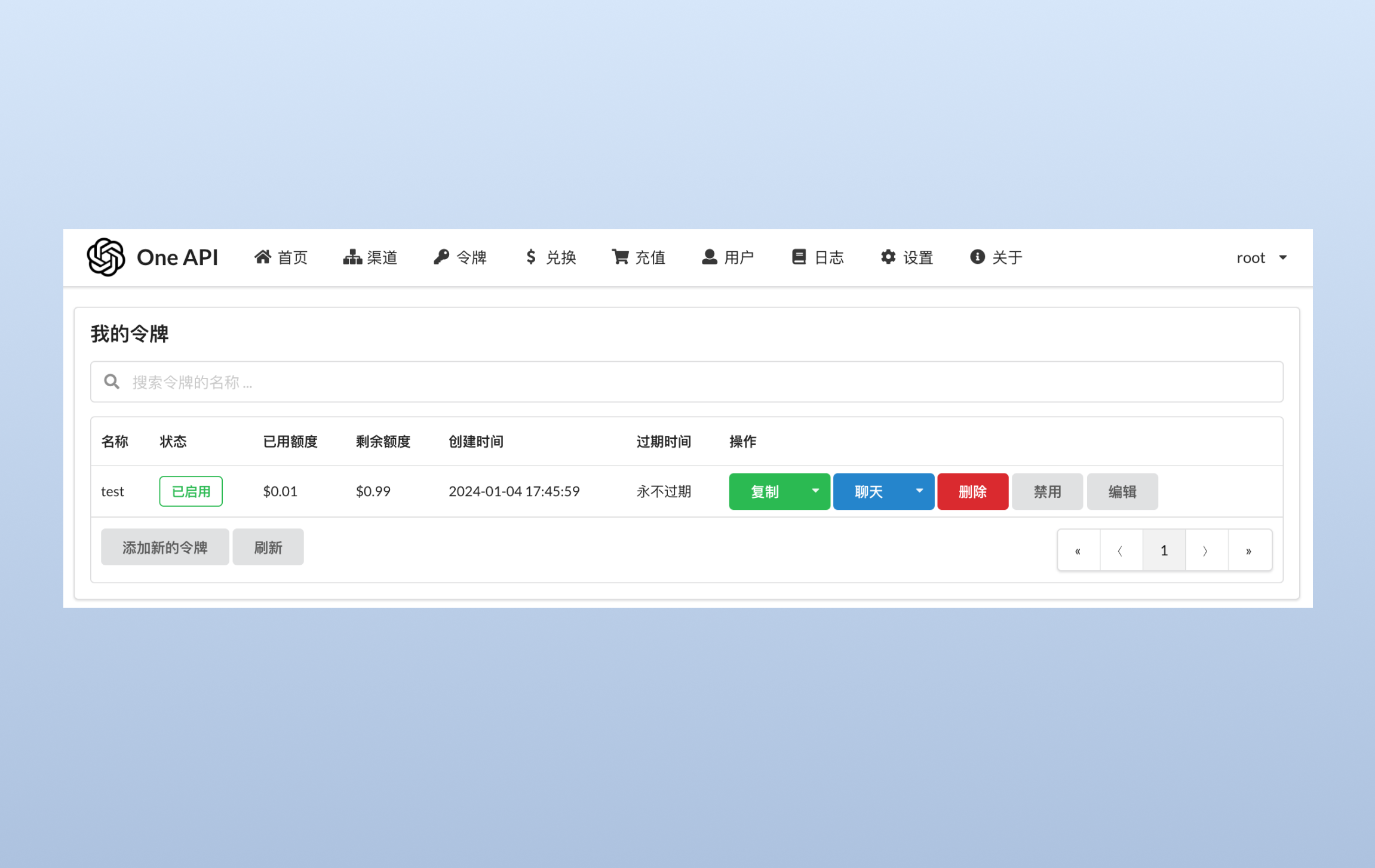
接下来我们还需要创建一个令牌,用于在 FastGPT 中访问 One API:
3.2 FastGPT 的安装和部署
FastGPT 的安装和部署可以参考 FastGPT 的官方文档,推荐使用 Docker Compose 快速进行部署。
创建目录并下载 docker-compose.yml:
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
修改下面两个环境变量,从而让 FastGPT 去请求 One API,再由 One API 去请求 Xinference 中的模型。因为刚刚我们在宿主机的 3001 端口启动了 one-api,
因此可以写 http://host.docker.internal:3001/v1,注意,这里必须加 /v1。
OPENAI_BASE_URL=http://host.docker.internal:3001/v1
CHAT_API_KEY=sk-xxxxxx
修改 FastGPT 的 config.json 配置文件,其中 chatModels(对话模型)用于聊天对话,cqModels(问题分类模型)用来对问题进行分类,extractModels(内容提取模型)则用来进行工具选择。在接下来的教程中我们将看到“问题分类模型”和“内容提取模型”在一个复杂工作流中扮演的作用。
{
"chatModels": [
...
{
"model": "qwen-chat",
"name": "Qwen",
"maxContext": 2048,
"maxResponse": 2048,
"quoteMaxToken": 2000,
"maxTemperature": 1,
"vision": false,
"defaultSystemChatPrompt": ""
}
...
],
"cqModels": [
...
{
"model": "qwen-chat",
"name": "Qwen",
"maxContext": 2048,
"maxResponse": 2048,
"inputPrice": 0,
"outputPrice": 0,
"toolChoice": true,
"functionPrompt": ""
}
...
],
"extractModels": [
...
{
"model": "qwen-chat",
"name": "Qwen",
"maxContext": 2048,
"maxResponse": 2048,
"inputPrice": 0,
"outputPrice": 0,
"toolChoice": true,
"functionPrompt": ""
}
...
]
}
然后启动容器,我们就可以在应用配置中选择 Qwen 模型进行对话:
docker-compose pull
docker-compose up -d
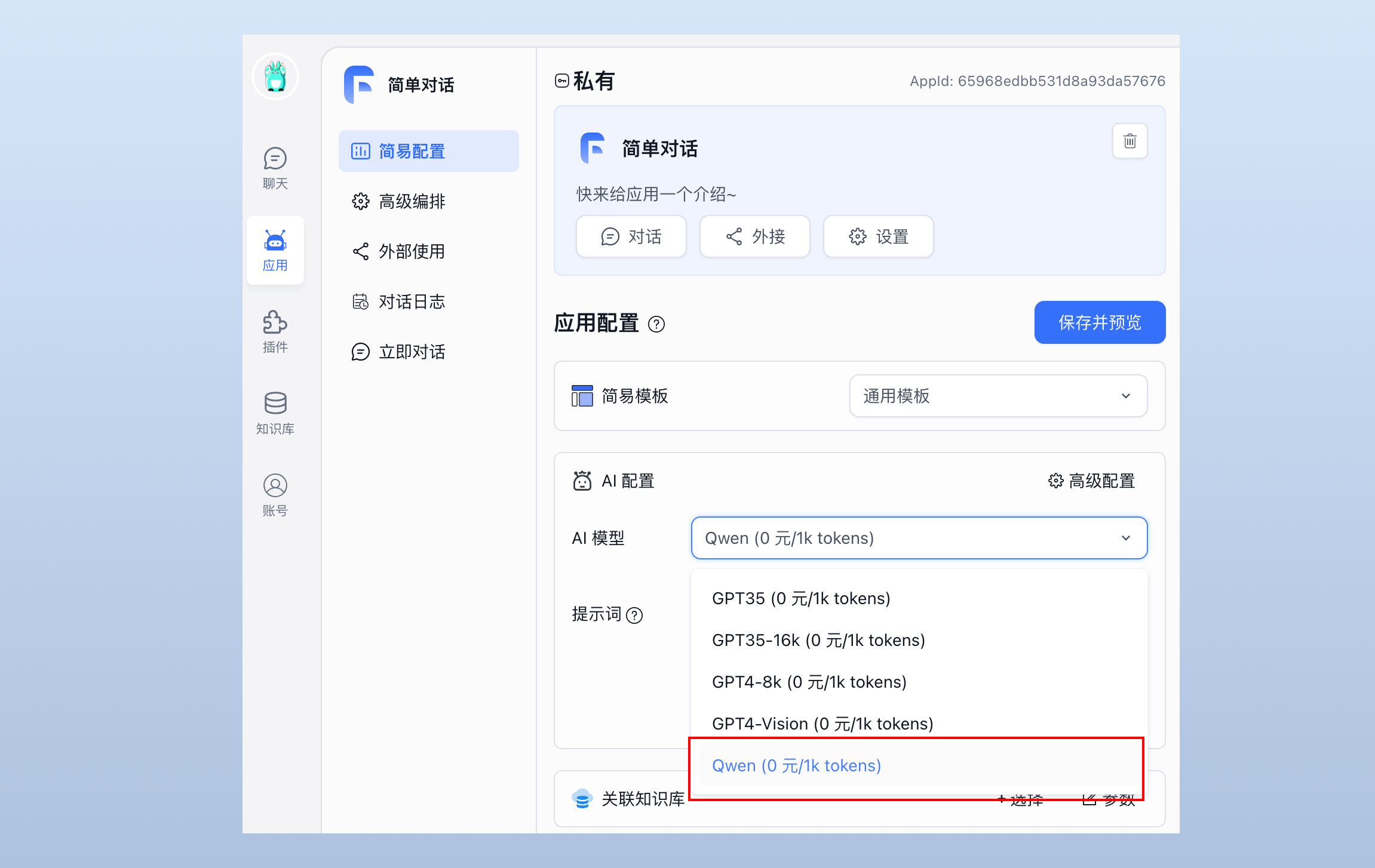
FastGPT 登录用户名为 root,密码为 docker-compose.yml 环境变量里设置的 DEFAULT_ROOT_PSW。
4. 通过 FastGPT 进行工作流编排
除了通过 Prompt 来配置聊天机器人的角色,FastGPT 还支持 Flow 节点编排的方式来实现复杂工作流,提高可玩性和扩展性, 这个功能上手的门槛,有一定开发背景的用户使用起来会比较容易。
接下来,我们将探索如何通过 FastGPT 提供的高级编排功能,来构建一个 AI 应用。
这个应用将实现如下的功能:
-
用户问题分类:对于用户输入的问题,通过“问题分类”模块进行区分,分出“询问天气”、“其他问题”。
-
对于 “询问天气” 的情况:
-
参数提取: 使用“文本内容提取”模块,从用户的问题中提取出“城市”。
-
第三方 API 调用:使用“HTTP 模块”调用第三方 API 查询天气(后文会介绍)。
-
文本加工:由于 API 的返回是 json 格式,我们使用“文本加工”模块对结果中的字段进行提取。
-
AI 总结回复:将解析出来的结果丢给“AI 对话”模块,让它根据结果来给出回答。
-
-
对于其他问题,直接走“AI 对话”模块,跟普通的 GPT 聊天一样。
4.1 用户问题分类
首先,对于用户输入的问题,通过“问题分类”模块进行区分,分出“询问天气”、“其他问题”。注意,“分类模型”选择 Qwen。
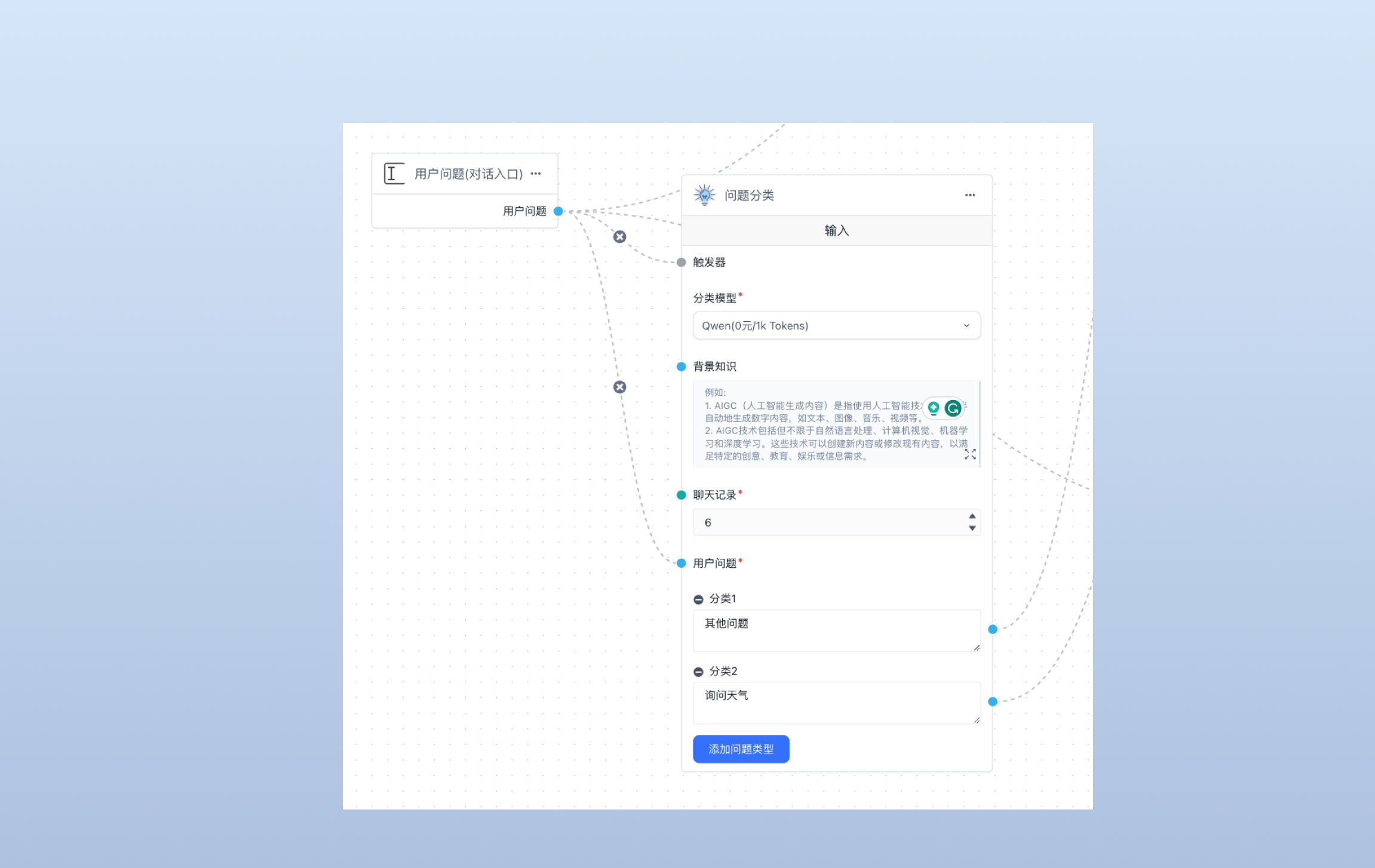
4.2 参数提取
由于天气接口需要传入的是“城市”字段,所以需要使用“文本内容提取”模块从用户的问题中提取出“城市”字段,若提取成功,将提取出来的“城市”发给“HTTP 模块”(下文会讲)。注意这里我需要指定“提取模型”为 Qwen。
提示词如下:
你是一个天气查询助手。根据用户问题,提取出城市。注意不是简单的文本提取,而是上下文理解后的提取。如果用户问题中不包含城市则不提取
为了提高用户体验,当“提取字段缺失”时,我们就用“指定回复”模块来提示用户输入城市:
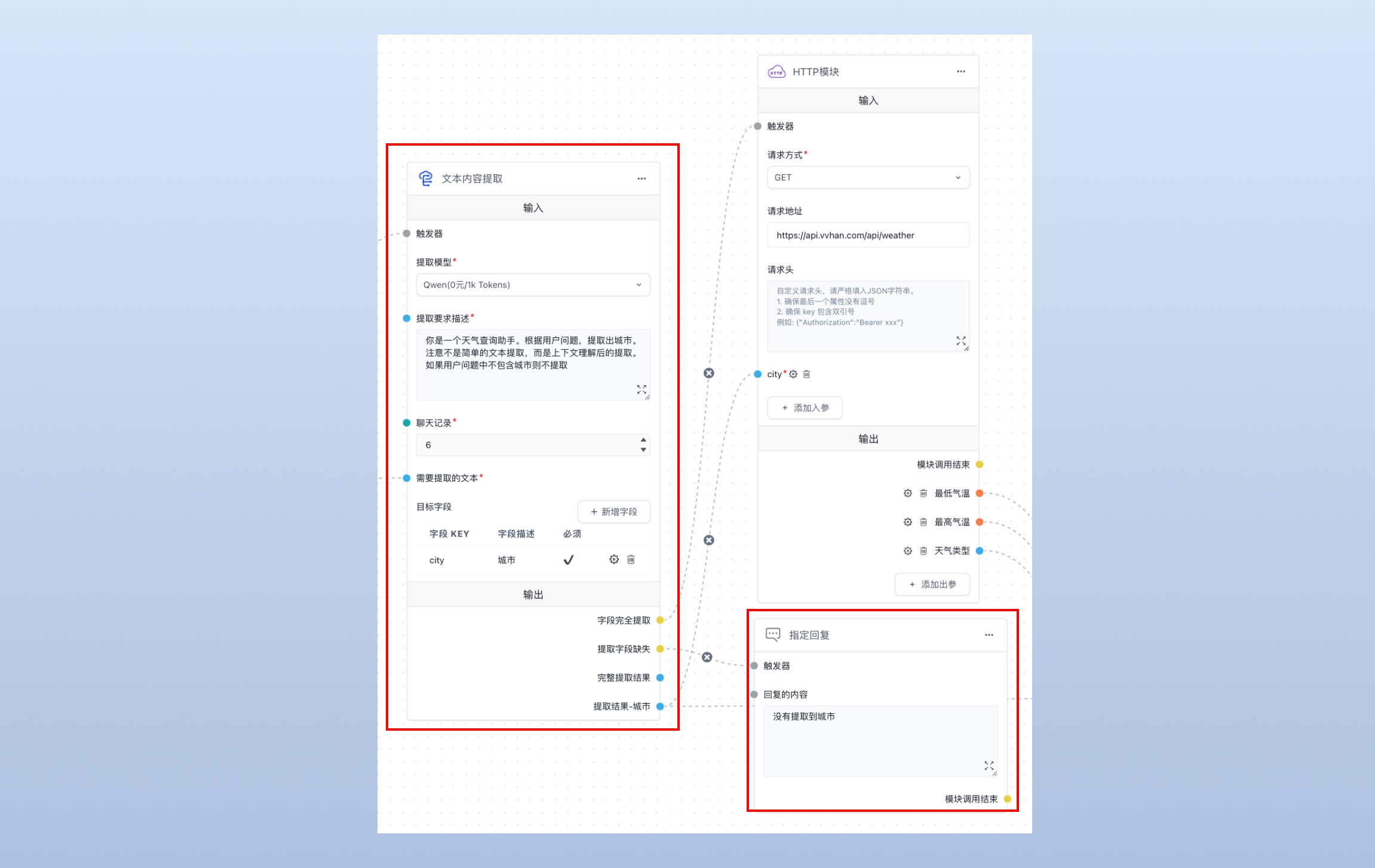
4.3 第三方 API 调用
首先,我们在 https://api.vvhan.com/ 这个网站找到一个能够查询某个城市天气情况的 API 接口,这里也可以替换成其他的公开 API 服务。
GET 请求样例:
curl https://api.vvhan.com/api/weather?city=上海
接口测试返回数据:
{
"date": "2024-01-04",
"week": "星期四",
"type": "阴",
"low": "3°C",
"high": "9°C",
"fengxiang": "微风",
"fengli": "1-3级",
"night": {
"type": "阴",
"fengxiang": "微风",
"fengli": "1-3级"
},
"air": {
"aqi": 103,
"aqi_level": 3,
"aqi_name": "轻度污染",
"co": "1",
"no2": "39",
"o3": "111",
"pm10": "93",
"pm2.5": "77",
"so2": "10"
},
"tip": "天有点冷,注意保暖~ 现在的温度比较凉爽~"
}
我们在 FastGPT 中创建“HTTP 模块”,选择请求方式为“GET”,填写请求地址为 https://api.vvhan.com/api/weather,并配置参数 city,最后连接上一步中我们创建的“参数提取”模块。

4.4 文本加工
由于 API 的返回是 json 格式,我们使用“文本加工”模块对结果中的字段进行提取,并且转化为一个完整的文本字符串,然后丢给 AI 对话模块(见下文),我们需要提取的字段如下:
- city: 城市(来自内容提取模块)
- type: 天气类型(来自 HTTP 模块)
- high: 最高气温(来自 HTTP 模块)
- low:最低气温(来自 HTTP 模块)
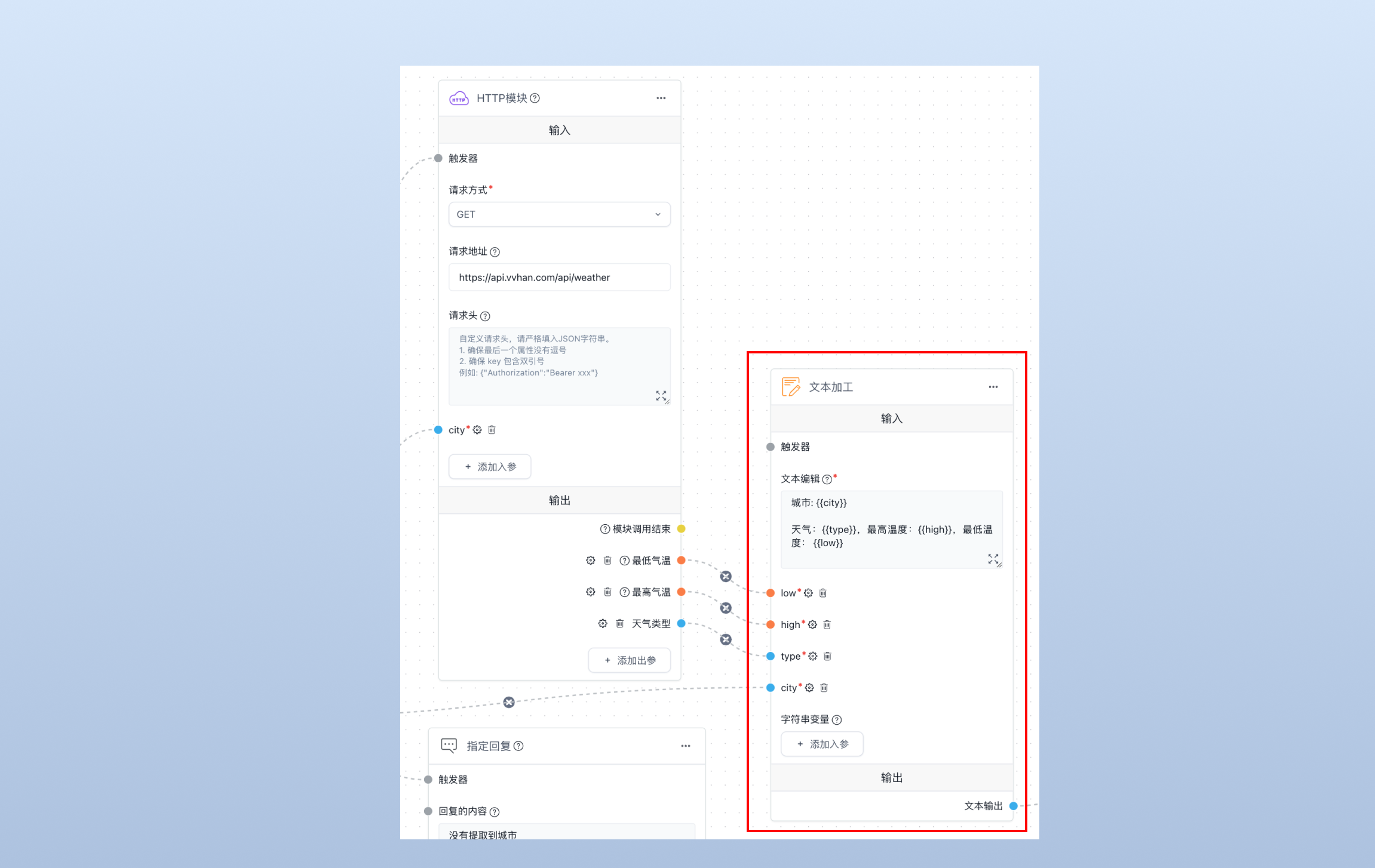
4.5 AI 总结回复
上述步骤已经利用 API 的返回拼装出了含有某个城市查询天气情况的所有信息,我们用 “AI对话” 模块来总结回复,记得将对话模型切换为 Qwen。
这里我所使用的提示词是(你也可以换成其他的):
已知条件:1. 当前时间是;2. 这个文本是要询问的地方的天气数据,比如用户问的是“北京”的天气,那这个文本就是“北京”的天气数据。
现在回复用户

最后我们来看下效果图:
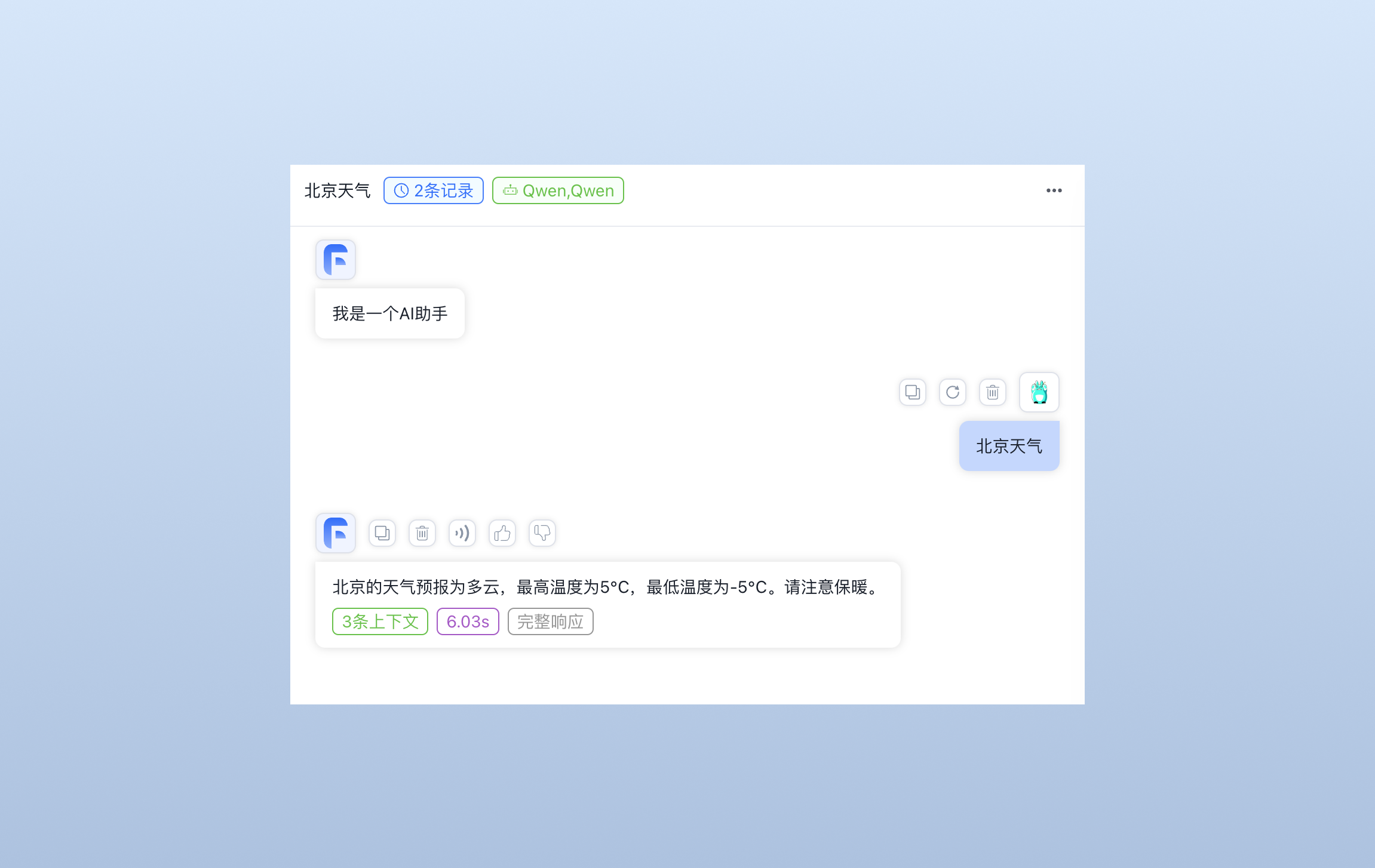
总结
本教程展示了如何通过集成 FastGPT 和 Xinference 来开发一个完全本地的 AI 应用,从环境搭建,到模型部署,再到应用编排, 帮助你掌握利用大型语言模型来解决实际问题的技巧,希望你在构建和落地 AI 解决方案的旅程中一帆风顺!

