 Dreamsome
2023.11.23
Dreamsome
2023.11.23

在 ChatGPT 发布后的这一年里,大语言模型(LLM)引起了全球开发者社区的广泛关注。大型语言模型(LLM)已经成为全球科技领域的一个热点话题, 吸引了来自世界各地的开发者们的密切关注。这不仅是一场技术革命的序幕,也是对未来人机交互方式的一次大胆预测。在这篇文章中,我们将深入了解大型语言模型(LLM)在应用开发中的作用,主要演示如何通过 Xinference 来部署一个开源 LLM——Qwen-14B,并且在这个模型基础之上,使用 LangChain 来构建一个能够阅读文档并回答问题的 AI 应用。
什么是 LLM?
LLMs 是一种机器学习模型,能够生成类似于人类语言的文本,并能以自然的方式理解指令。这些模型通过分析大量的书籍、文章、网站等数据集来进行训练, 通过挖掘这些数据中的统计规律,预测在某个给定输入之后最可能出现的词语或短语。
什么是 LangChain 🦜🔗 ?
LangChain 是一个专为开发者设计的开源编程框架,旨在帮助他们利用大型语言模型(LLMs)打造各种应用。无论是聊天机器人、生成式问答系统, 还是内容摘要工具,LangChain 都能通过灵活串联多个模块的组件,使开发者能够充分发挥 LLM 的强大能力,打造出卓越的应用程序。
什么是 Xinference?
Xinference 是一个专为大型语言模型(LLM)、语音识别模型和多模态模型设计的开源模型推理平台,支持私有化部署。 它提供多种灵活的 API 和接口,包括 RPC、与 OpenAI API 兼容的 RESTful API、CLI 和 WebUI,并集成了 LangChain、LlamaIndex 和 Dify 等第三方开发者工具,便于模型的集成和开发。Xinference 支持多种推理引擎(如 Transformers、vLLM 和 GGML),并适用于不同硬件环境, Xinference 还支持分布式多机部署,能够在多个设备或机器间高效分配模型推理任务,满足多模型和高可用的部署需要。
概览
在本文中,我将向你展示如何从头开始,利用 Xinferece 部署 Qwen-14B 开源模型,并通过 LangChain 的链式调用来访问它,最后用 Streamlit 来创建一个最小可行 Demo , 以下是这篇文章的概览:
- 设置环境和安装依赖
- 在本地机器上安装 Xinferece
- 部署 Qwen-14B 模型
- 通过 LangChain 链式调用访问 LLM
- 利用 Embedding 让 LLM 访问数据
- 用 Streamlit 实现一个 Demo
1.设置环境和安装依赖
Python 环境
首先我们需要准备一个 3.9 以上的 Python 环境运行来 Xinference,建议先根据 conda 官网文档安装 conda。 然后使用以下命令来创建 3.11 的 Python 环境:
conda create --name py311 python=3.11
conda activate py311
安装 CUDA
假设你服务器配备 NVIDIA 显卡,推荐先安装 CUDA,从而让 Xinference 最大限度地利用显卡的加速功能。
Windows 环境
- 打开 NVIDIA 官网 CUDA 下载页,然后根据页面的提示下载安装程序。
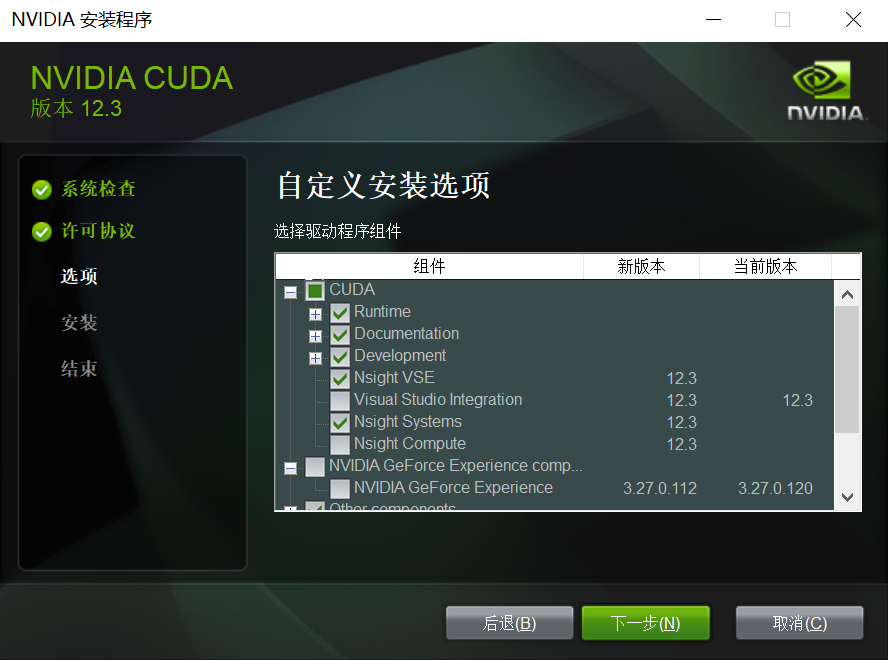
- 双击安装程序,如果安装败请在第三步中选择“自定义安装选项”:
- 如果你的机器上没有安装 Visual Studio,取消勾选“Visual Studio Integration”。
- 如果安装程序显示“Nsight Compute”安装失败,取消勾选“Nsight Compute”。
- 其他的选项,例如“NVIDIA GeForce Experience”,如果你的机器上已安装,则取消勾选。
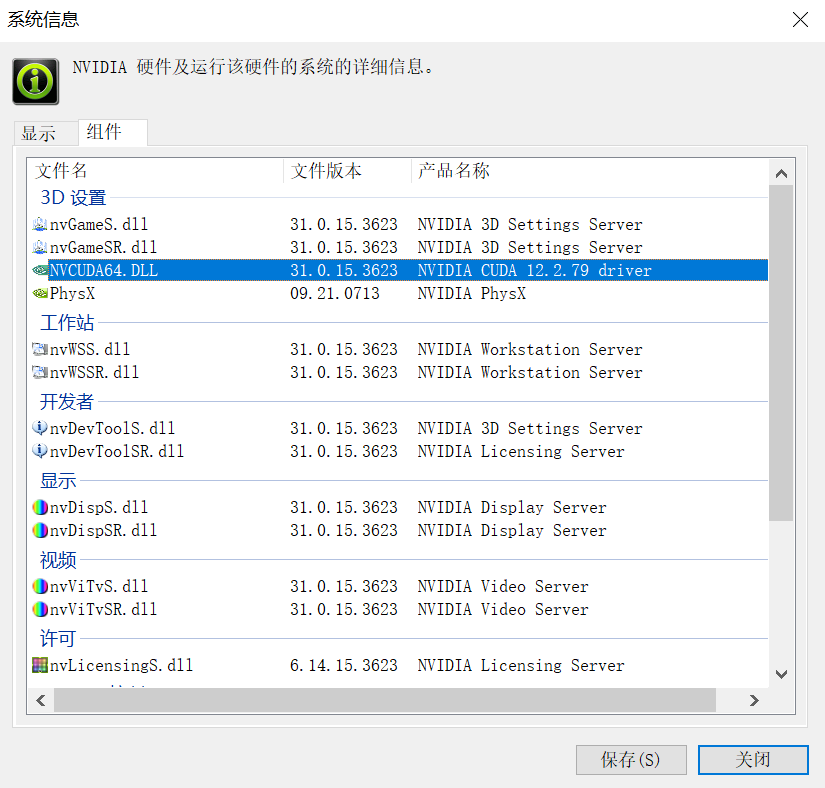
- 安装完毕后,打开“NVIDIA 控制面板”,可以看到 CUDA 已经安装:
Windows WSL 环境
- 管理员身份运行 CMD,通过
wsl --install或wsl --install -d <OS>命令安装 WSL Ubuntu 版本。 - 安装完成后使用
wsl命令进入 Linux。 - 打开 NVIDIA 官网 CUDA 下载页,在页面上选择你的操作系统类型、版本和安装方式,然后根据页面的提示进行安装。注意,Distribution 一定要选择 WSL-Ubuntu。
- 安装 CUDA 完成后,使用 nvidia-smi 命令验证,如能出现你的显卡信息,则表示安装成功。
Linux 环境
- 打开 NVIDIA 官网 CUDA 下载页,在页面上选择你的操作系统类型、版本和安装方式,然后根据页面的提示进行安装。
- 安装完成后建议重启机器。
- 使用 nvidia-smi 命令验证,如能出现你的显卡信息,则表示安装成功。
2.在本地机器上安装 Xinference
Xinference 支持多种推理引擎作为后端,例如 Transformers,CTransformers 和 vLLM,以满足不同部署场景下部署大模型的需要,下面我会分使用场景来介绍一下这三种推理后端,以及他们的安装方法。
服务器
如果你希望在一台 Linux 或者 Window 服务器上部署大模型,请安装 Transformers 或 vLLM 后端:
-
Transformers :通过集成 Huggingface 的 Transformers 库作为后端,Xinference 可以以最快的速度集成当今自然语言处理(NLP) 领域的最前沿模型(自然也包括 LLM)。
-
vLLM: vLLM 是由加州大学伯克利分校开发的一个开源库,专为高效服务大型语言模型(LLM)而设计。它引入了 PagedAttention 算法, 通过有效管理注意力键和值来改善内存管理,吞吐量能够达到 Transformers 的 24 倍,因此 vLLM 适合在生产环境中使用,应对高并发的用户访问。
以下两条命令在安装 Xinference 时,将安装 Transformers 和 vLLM 作为 Xinference 的推理引擎后端:
pip install "xinference[transformers]"
pip install "xinference[vllm]"
pip install "xinference[transformers,vllm]" # 同时安装
PyPi 在 安装 Transformers 和 vLLM 时会自动安装 PyTorch,但自动安装的 CUDA 版本可能与你的环境不匹配,此时你可以根据 PyTorch 官网中的安装指南来手动安装。
个人设备
如果你想在自己的 Macbook 或者个人电脑上部署大模型,推荐安装 CTransformers 作为 Xinference 的推理后端。CTransformers 是用 GGML 实现的 C++ 版本 Transformers。
GGML 是一个能让大语言模型在消费级硬件上运行的 C++ 库。 GGML 最大的特色在于模型量化。量化一个大语言模型其实就是降低权重表示精度的过程,从而减少使用模型所需的资源。 例如,表示一个高精度浮点数(例如 0.0001)比表示一个低精度浮点数(例如 0.1)需要更多空间。由于 LLM 在推理时需要加载到内存中的,因此你需要花费硬盘空间来存储它们,并且在执行期间有足够大的 RAM 来加载它们, GGML 支持许多不同的量化策略,每种策略在效率和性能之间提供不同的权衡。
通过以下命令来安装 CTransformers 作为 Xinference 的推理后端:
pip install xinference
pip install ctransformers
因为 GGML 是一个 C++ 库,Xinference 通过 llama-cpp-python 这个库来实现语言绑定。对于不同的硬件平台,我们需要使用不同的编译参数来安装:
- Apple Metal(MPS):
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python - Nvidia GPU:
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python - AMD GPU:
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
3.部署 Qwen-14B 模型
什么是 Qwen-14B?
Qwen-14B(通义千问-14B)是阿里云研发的通义千问大模型系列中具有 140 亿参数的模型。作为一款基于 Transformer 架构的大型语言模型, Qwen-14B 在广泛且多样化的预训练数据上进行了训练,这些数据包括大量网络文本、专业书籍和代码等。基于 Qwen-14B 的核心技术,开发团队还创建了 Qwen-14B-Chat, 一个结合对齐机制的 AI 助手,以提供更精准的语言模型服务。想要深入了解这个开源模型的具体细节,可以访问其 GitHub 代码库。
为了优化模型的内存使用,Xinference 提供了 Qwen-7B 和 Qwen-14B 的多种量化版本。在接下来的部分,我们将深入探索如何利用 Xinference 快速部署 Qwen-14B 模型, 体验它在实际应用中的高效和便捷。
启动 Xinference 模型服务
在本地中启动 Xinference 模型服务的方式非常简单,只是需要输入如下命令即可:
xinference-local -H 0.0.0.0
Xinference 默认会在本地启动服务,端口默认为 9997。因为这里配置了-H 0.0.0.0参数,非本地客户端也可以通过机器的 IP 地址来访问 Xinference 服务。除了单机部署模式,Xinference 模型服务还提供集群版的部署。
Web UI 方式启动模型
Xinference 启动之后,在浏览器中输入: http://localhost:9997,我们可以访问到本地 Xinference 的 Web UI:
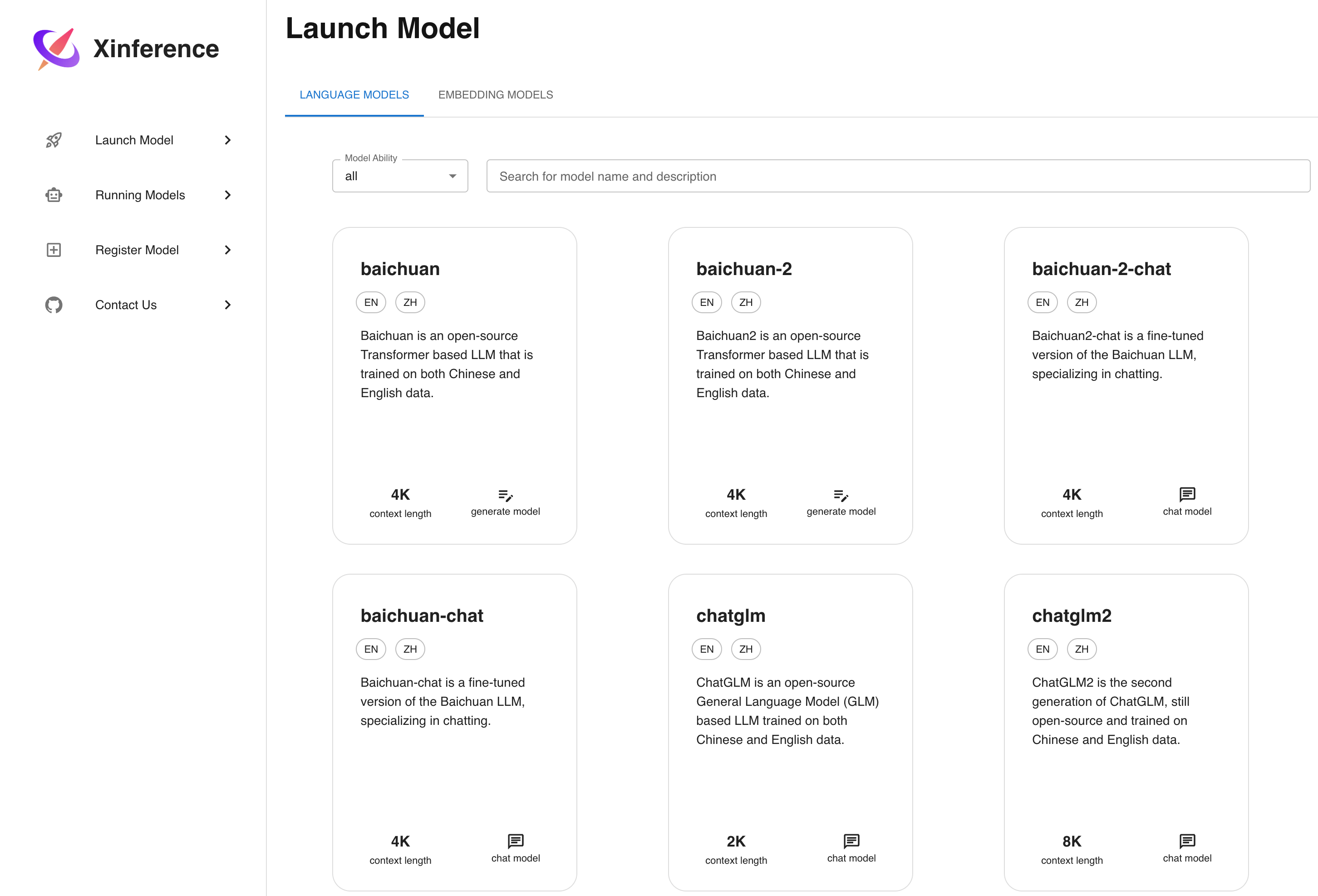
我们打开“Launch Model”标签,搜索到 qwen-chat,选择模型启动的相关参数,然后点击模型卡片左下方的小火箭🚀按钮,就可以部署该模型到 Xinference。

当你第一次启动 Qwen 模型时,Xinference 会从 HuggingFace 下载模型参数,大概需要几分钟的时间。Xinference 将模型文件缓存在本地,这样之后启动时就不需要重新下载了。
Xinference 还支持从其他模型站点下载模型文件,例如,如果您希望从 modelscope 下载模型,可以在启动 Xinference 时设置环境变量来实现这一点:
XINFERENCE_MODEL_SRC=modelscope xinference-local --H 0.0.0.0
命令行方式启动模型
我们也可以使用 Xinference 的命令行工具来启动模型,注意这里我们指定模型 UID 为 my_llm:
xinference launch -u my_llm -n qwen-chat -s 14 -f pytorch
除了 WebUI 和命令行工具, Xinference 还提供了 Python SDK 和 RESTful API 等多种交互方式, 更多用法可以参考 Xinference 官方文档。
4.通过 LangChain 链式调用访问 LLM
在上一部分中,我们利用 Xinference 提供的模型服务在本地成功部署了大型语言模型(LLM)——Qwen。接下来,我们将探索如何通过 LangChain 框架开发基于大型语言模型的应用程序。
在深入 LangChain 的编程接口之前,我们首先需要理解一个关键概念——“提示词”。大型语言模型的交互主要依靠文本:我们向模型提供一段文本,模型随后返回一段新的文本。 模型的响应质量和准确性与我们的提问方式紧密相关。通过提供清晰、具体且针对性的指令,我们可以帮助 AI 更准确地理解我们的问题。这种设计和优化提示词的技巧被称为“提示词工程”。
LangChain 旨在简化提示词的生成过程。它提供了多个类和函数,以及“提示词模板”(PromptTemplate)来简化构建和处理提示词的流程。简而言之,提示词模板是一种结合了文本字符串模板和一组用户定义参数的工具。我们接下来通过一个实例来具体说明这一点。
注意,我们再初始化 Xinference 对象时,除了指向本地的 Xinference 端点,model_uid 也需要指定为我们刚刚启动的模型 UID。
from langchain.llms import Xinference
from langchain.prompts import PromptTemplate
llm = Xinference(server_url="http://localhost:9997", model_uid="my_llm")
template = """Q: 小说《{novel_name}》的作者是谁?只说名字
A: """
prompt_template = PromptTemplate.from_template(template)
print(prompt_template.input_variables)
>>> ['movie_name']
# 格式化 PromptTemplate
formatted_prompt = prompt_template.format(novel_name="看不见的城市")
print(formatted_prompt)
>>> 'Q: 小说《看不见的城市》的作者是谁?只说名字\n\nA: '
response = llm(prompt=formatted_prompt, stop=["Q:", "\n"])
print(response)
>>> '伊塔洛·卡尔维诺。'
在上述示例中,我们仅单次调用了大型语言模型(LLM)。然而,对于更复杂的应用场景,通常需要将 LLM 与其他组件相结合。 正如 LangChain 名称所暗示的那样,其核心特色在于“链式调用”——这意味着 LangChain 能够将多个处理文本的组件连起来,以此来打造更加复杂和功能丰富的应用程序。
为了深入理解这个概念,我们可以构建一个 SequentialChain 作为实践。通过这种方式,我们不仅能够查询一个小说作者的信息, 还能进一步获取其英文名,展示了链式调用在处理连续查询中的实际应用。
from langchain.llms import Xinference
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, SequentialChain
llm = Xinference(server_url="http://localhost:9997", model_uid="my_llm")
q1_template = """Q: 小说《{novel_name}》的作者是谁?只说名字
A: """
q2_template = """Q: {author_name} 的英文名是什么?只说名字
A: """
q1_prompt_template = PromptTemplate.from_template(q1_template)
q2_prompt_template = PromptTemplate.from_template(q2_template)
chain1 = LLMChain(llm=llm, prompt=q1_prompt_template, output_key="author_name")
chain2 = LLMChain(llm=llm, prompt=q2_prompt_template)
sequential_chain = SequentialChain(chains=[chain1, chain2], input_variables=["novel_name"])
answer = sequential_chain.run(novel_name="看不见的城市", stop=["Q:", "\n"])
print(answer)
>>> '伊塔洛·卡尔维诺的英文名是Italo Calvino。'
5.利用 Embedding 让 LLM 访问数据
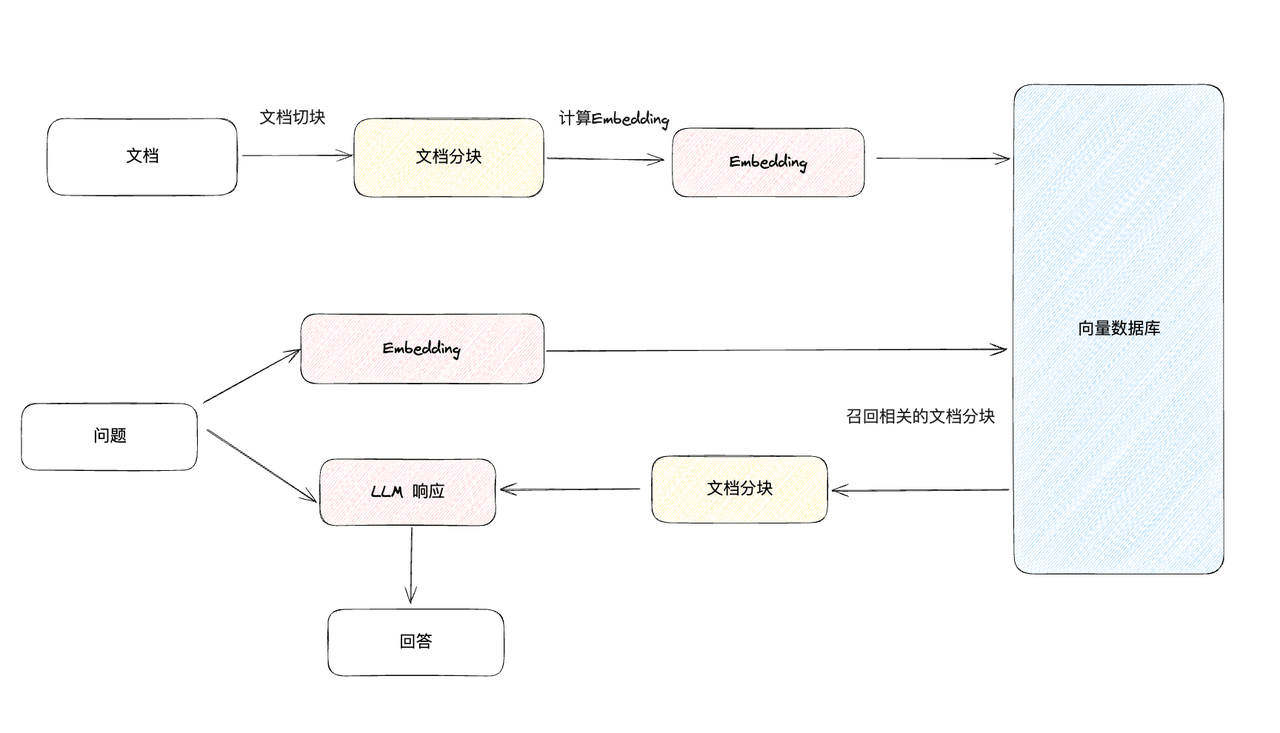
在实际应用中,由于大型语言模型(LLM)在训练阶段并未接触到用户的私有数据,因此,要使这些模型能够有效地利用这些特定信息, LLM 应用程序需具备访问外部数据源的能力。构建一个能对文档进行问答的应用,通常需要经历以下关键阶段:
- 文档加载:用来将外部数据加载为文档。
- 文档处理:把文档分割成更小的切片。
- Embedding:将文本分片转换为向量表示。
- 向量存储:将向量存储在向量数据库中。
- 语义检索:对于输入的问题,检索与它最相似的向量。
在开始编码之前,我们需要准备一份用来测试的文本。我从网上搜索了一篇关于金庸作品介绍的文章,你也可以换成自己的文档中的内容。
“飞雪连天射白鹿,笑书神侠倚碧鸳”,作此对联者,正是金庸先生本人,这十四字代表他的十四部小说。
2018年10月30日,金庸先生离开了我们,但却给我们留下了一个个快意恩仇的江湖世界。
按金庸创作时间顺序的排名:
1.《书剑恩仇录》(1955 年)
2.《碧血剑》(1956 年)
3.《雪山飞狐》(1957 年)
4.《射雕英雄传》(1958 年)
5.《神雕侠侣》(1959 年)
6.《飞狐外传》 (1959 年)
7.《白马啸西风》(1960 年)
8.《鸳鸯刀》(1961 年)
9.《连城诀》(1963 年)
10.《倚天屠龙记》(1964 年)
11.《天龙八部》(1965 年)
12.《侠客行》(1965 年)
13.《笑傲江湖》(1967 年)
14.《鹿鼎记》(1969-1972 年)
需要说明的是,金庸自1955 年闯入武侠世界,至1972 年9 月封笔, 前后十七年写了十五部作品。另有《越女剑》短篇(1970 年),因其容量较小,又受对联字数限制,金庸不列其内。
加载和处理文档
这段代码展示了如何使用 LangChain 来加载和分割一个文本文件。首先,它利用 TextLoader 加载我们准备好的测试文件。接着,我们使用 CharacterTextSplitter
来分割这个文本文件,它会在 \n\n 分隔符处进行分割,并尽可能将文本分割成每块最多 300 个字符的小块。
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
loader = TextLoader("./raw.txt")
docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
print(texts[0].page_content)
>>> '“飞雪连天射白鹿,笑书神侠倚碧鸳”,作此对联者,正是金庸先生本人,这十四字代表他的十四部小说。\n\n2018年10月30日,金庸先生离开了我们,但却给我们留下了一个个快意恩仇的江湖世界。\n\n按金庸创作时间顺序的排名:'
创建 Embeddings
在大型语言模型(LLM)应用开发中,Embedding 技术扮演了极其重要的角色。Embedding 是将词汇、短语、句子或整个文档转换为密集的数值向量的过程。 这些向量能够捕捉到文本的语义信息,并以一种计算机能够理解的格式表示出来。
在我们开始用 LangChain 为文本创建 Embedding 之前,我们还需要在本地部署一个 Embedding 模型,这里我选的是 bge-base-zh-v1.5 ,也就是 BAAI general embedding(简称 BGE),你也可以换成其他的模型,用下面这条命令就可以在 Xinference 中一键部署:
xinference launch -u my_embedding -n bge-base-zh-v1.5 -t embedding
接下来,我们试着调用下 LangChain 中和 Embedding 相关的两个方法:embed_documents 用于嵌入文档,embed_query 用于嵌入问题,可以看到
BGE 模型为文档和问题生成了 768 维的向量:
from langchain.embeddings import XinferenceEmbeddings
embeddings = XinferenceEmbeddings(server_url="http://127.0.0.1:9997", model_uid="my_embedding")
embeded_texts = embeddings.embed_documents([t.page_content for t in texts])
len(embeded_texts), len(embeded_texts[0])
>>> (13, 768)
query = "鹿鼎记的主角是谁?"
embeded_query = embeddings.embed_query(query)
embeded_query[:4]
>>> [0.02611861750483513, -0.0253167562186718, -0.008166748099029064, 0.0379350483417511]
向量存储与文档检索
向量存储是一种高效管理 Embedding 存储并提供向量搜索的工具。在查询过程中,我们可以对问题也进行 Embedding 化,然后检索到与它最相似的向量,从而为 LLM 召回所有相关的上下文信息。
这里我们会用到 Chroma,这是一个专为 AI 应用开发而设计的嵌入式向量库,我们可以通过 pip install chromadb 命令在本地机器上进行安装。
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
query = "天龙八部的主角是谁?"
query_vector = embeddings.embed_query (query)
docs = db.similarity_search_by_vector(query_vector, k=1)
docs.page_content
>>> '《天龙八部》中有三个主角:段誉、乔峰、虚竹,一公子一英雄一和尚。三人身分不同,经历不同,性格不同,但各占一台戏,既前后交错,又相互映衬,既层次鲜明,又一气呵成。这种结构与人物刻画手法,开创了武侠小说写人叙事的新路子。\n\n1、《笑傲江湖》:一部真正伟大的文学巨著,必然同时具有结构上的严谨与丰富,内容上的壮阔与细腻,语言上的生动与流畅,情节上的跌宕与曲折,主题上的深刻与浩瀚。无论从哪一个角度去认识《笑傲江湖》,我们都不会感到失望。它可以说是武侠世界中空前的惊世之作。'
下面我们可以把检索到的这部分内容作为上下文,传给大语言模型 (LLM),这里会用到我们在上一个章节中学习过的 LLMChain 这个类 ,它将基于我们提供的信息,生成一个答案:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
template ="""
使用下面的上下文来回答问题。
如果你不知道答案,就说你不知道,不要编造答案。
{context}
问题: {question}
回答:"""
prompt = PromptTemplate.from_template(template)
prompt.input_variables
>>> ['context', 'question']
query = "哪部作品的主人公叫胡斐?"
similar_doc = db.similarity_search(query, k=1)
context = similar_doc[0].page_content
print(context)
>>> '《飞狐外传》的成功,不单单是这部书悬念迭起,情节精彩纷呈,还因为作者第一次完成了一个既有侠义心肠又具有一般人弱点的少年英雄的塑造。胡斐的天真、调皮、机智、不拘小节,都显示了一个少年人的特点,读来十分亲切。'
query_llm = LLMChain(llm=llm, prompt=prompt)
response = query_llm.run({"context": context, "question": query})
print(response)
>>> '《飞狐外传》的主人公叫胡斐。'
不要小看提示词在这里发挥的作用,通过精心设计的提示,我们可以减少大语言模型产生幻觉的风险——在不确定性面前,它可能会虚构事实。
到目前为止,我们已经跑通了问答机器人的基本功能,而且完全依赖于本地的 LLM 模型!
6.用 Streamlit 实现一个 Demo
最后,你可以尝试用之前提到过的这些关键步骤来构建一个 Demo,允许用户上传任何 TXT 文件,然后对文件进行提问……下面是它运行起来的样子:

我提供了完整的 Streamlit 代码,你可以根据自己的需要来扩展它,让它支持其他文件类型(例如 PDF、Word),你也可以用 Xinference 部署 Qwen 之外的其他 LLM, 来测试不同 LLM 在你的应用中的表现。
import streamlit as st
from langchain.llms import Xinference
from langchain.embeddings import XinferenceEmbeddings
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Customize the layout
st.set_page_config(page_title="Local AI Chat Powered by Xinference", page_icon="🤖", layout="wide")
# Write uploaded file in temp dir
def write_text_file(content, file_path):
try:
with open(file_path, 'w') as file:
file.write(content)
return True
except Exception as e:
print(f"Error occurred while writing the file: {e}")
return False
# Prepare prompt template
prompt_template = """
使用下面的上下文来回答问题。
如果你不知道答案,就说你不知道,不要编造答案。
{context}
问题: {question}
回答:"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
# Initialize the Xinference LLM & Embeddings
xinference_server_url = "http://localhost:9997"
llm = Xinference(server_url=xinference_server_url, model_uid="my_llm")
embeddings = XinferenceEmbeddings(server_url=xinference_server_url, model_uid="my_embedding")
llm_chain = LLMChain(llm=llm, prompt=prompt)
st.title("📄文档对话")
uploaded_file = st.file_uploader("上传文件", type="txt")
if uploaded_file is not None:
content = uploaded_file.read().decode('utf-8')
file_path = "/tmp/file.txt"
write_text_file(content, file_path)
loader = TextLoader(file_path)
docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
db = Chroma.from_documents(texts, embeddings)
st.success("上传文档成功")
# Query through LLM
question = st.text_input("提问", placeholder="请问我任何关于文章的问题", disabled=not uploaded_file)
if question:
similar_doc = db.similarity_search(question, k=1)
st.write("相关上下文:")
st.write(similar_doc)
context = similar_doc[0].page_content
query_llm = LLMChain(llm=llm, prompt=prompt)
response = query_llm.run({"context": context, "question": question})
st.write(f"回答:{response}")
随着我们的探索接近尾声,我们希望这篇文章不仅为您提供了一个清晰的指引,展示了如何结合 LangChain、Xinference 以及其他先进工具来开发一个简单的 AI 应用, 从环境搭建,到模型部署,再到应用实现,帮助你掌握利用大型语言模型来解决实际问题的技巧,希望你在构建和落地 AI 解决方案的旅程中一切顺利!

