 Chris Qin
2023.02.06
Chris Qin
2023.02.06

现在,我们非常高兴地宣布 Xorbits,加速 Python 数据处理和 AI 的全新开源框架。
背景
2023年,ChatGPT 又让 AI 再次火了一把。人们都在谈论它的魔力,AI 仿佛一夜之间就要改变世界。但是,我们都知道,我们离真正强人工智能还有很远的路。

ChatGPT 使用图示
除了强人工智能,我们在把 AI 真正应用到我们的日常工作、产品中,免不了碰到很多问题,其中著名的一个问题是,其实在 AI 的开发中,真正机器学习的部分只是一小部分,大部分的工作还是围绕数据的处理展开。数据处理和 AI 已经很难割舍了。
更重要的是,在数据处理和 AI 整个领域,存在着太多的“裂缝”。
开发效率和运行效率的裂缝
很多人说“效率”,其实效率分两种,开发效率和运行效率。这两者很多时候无法兼得。拿编程语言举例子,Python 开发效率特别高,用 Python 实现任何想法都可以很快完成;但 Python 很多时候运行效率就不够,如果是计算密集型的应用,Python 会变得非常慢;C++ 则运行效率高得多,但如果论开发,C++ 确实比 Python 要慢得多。再拿 TensorFlow 和 PyTorch 举例,早期 TensorFlow 讲究计算图,把代码生成一个计算图再提交,运行效率确实可以很快,但构图过程太难用了,对用户很不友好,所以开发效率就相应变低了;PyTorch 则更注重开发效率,用 Pythonic 的方式来编写人工智能程序,用户写的就是 Python,但运行效率可能就没有那么快。
开发效率在我看来,是第一要解决的事情,因为,如果开发效率跟不上,性能再好也无济于事。脑子中有大把好的想法,但如果来不及实现,那么于事无补。对于数据处理和 AI,Python 是非常好的语言,因为它可以最大程度发挥开发人员的效率,用简洁的语法,来实现更多的智能。
这也是 Python 为什么越来越流行的原因。
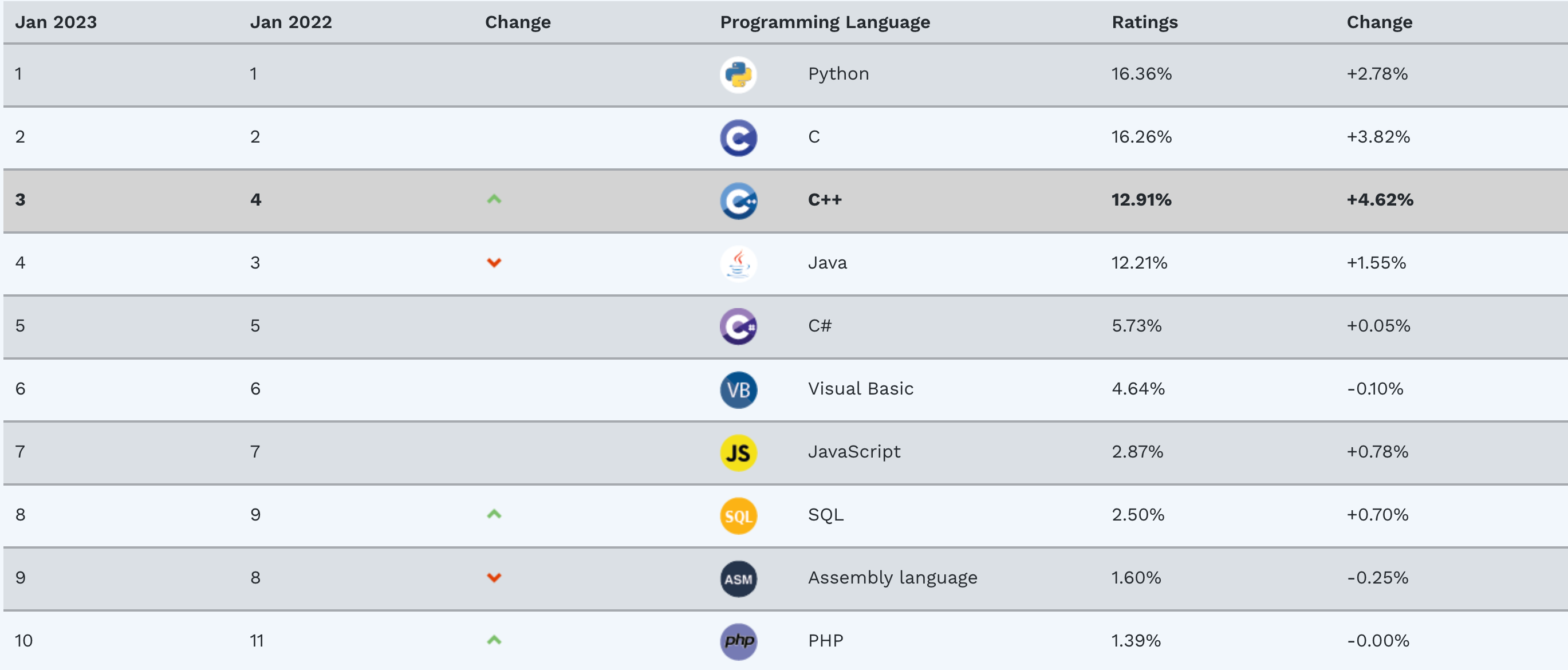
Tiobe Index

IEEE spectrum 编程语言排行
大数据和 AI 的裂缝

自从 2000 年初 Google 提出三驾马车开始,大数据越来越为人熟知,随着开源 Hadoop、Spark 等的兴起,以 Java 生态为首的大数据生态有了长足的进步。与此同时,AI 的开发领域,Python 语言是不二之选,深度学习框架 PyTorch、TensorFlow,传统机器学习库 scikit-learn、XGBoost、LightGBM 等等的主要开发语言都是 Python。通常,算法工程师弄一台机器、1张或几张卡,就工作起来了。
大数据系统往往惊人地复杂,它们往往有许多重型的调度底座,本身的部署、运维、使用都需要非常强的领域知识。大数据系统也往往以 SQL 为主要的编程语言为主,这些都与 AI 的开发技术栈有着巨大的裂缝。
但实际上,AI 的流程迭代就是从数据处理到算法,再到数据处理再算法,不断迭代的过程。这两个技术栈之间的巨大裂缝,会导致整个效率的极其低下。
数据科学家和数据工程师的裂缝
数据科学家在国内可能是一个新鲜的概念,但实际上,在国外,数据科学家已经非常常见。他们可能在产品、营销等各个团队,通过对数据进行统计、机器学习等方式,为业务提供有价值的分析和预测。他们用 Python 解决他们的问题,pandas、scikit-learn、PyTorch 可能是他们的强有力的工具。但当数据变大的时候,他们往往无能为力,因为这些工具就不是为大数据量而生。数据工程师的工作,就是帮助数据科学家把他们手上的分析运行在大数据平台,用 Spark 等工具运行。不难想象,这是多么艰难的一条路。
科学家和研究数据的裂缝
曾经有科学家找到我,物理学家、天文学家、地理学家他们的专业是科学,不是编程,所以,Python 是他们最能熟练掌握的工具,因为 Python 上有数不清的好用的库能帮他们解决各种科学问题。但科学领域往往有巨大的数据,一个卫星拍摄的一张图片可能就多达几个G了,更不用说卫星一直在拍摄。这些数据如何高效处理,是他们不能不面临的难题。
程序和算力的裂缝
AI 的发展中,越来越多的硬件加速器得到了应用,但是我们写的程序怎么样高效利用这些算力是很很难的问题。如果我们面对的是一个分布式的环境,那就更难了。
Xorbits 就是为了解决这些裂缝
我们成立一个创业公司未来速度(Xprobe Inc.),并推出 Xorbits 就是为了解决这些“裂缝”。
- Xoribts 把最常用的 Python 数据处理和 AI 的库做了加速,包括 numpy、pandas 等,用户可以保留很高的开发效率,毕竟他依然使用他最熟悉的开发栈。同时,Xorbits 在内部通过自动并行、分布式和硬件加速的方式,让用户的代码的运行效率也得到了提高。
- Xorbits 可以处理 TB 级的数据,这对于大部分公司来说都已经足够了。Pandas 接口强大的表达力,能够涵盖常用的 ETL、探索分析。Xorbits 的部署是云原生的,不再依赖复杂的 Hadoop 生态。大数据和 AI 不再需要依赖两个不同的技术栈。
- 数据科学家和数据工程师现在可以使用同一个技术栈,数据科学家最常用的库现在已经可以处理 TB 级,数据工程师们可以帮他们在同一个平台上进行优化,不同平台间的迁移也不再需要。
- 科学家们依赖的高维数据、时序、机器学习的能力,Xorbits 正在逐渐支持。可以想象到,未来这些海量数据的科学数据的处理会比现在更美好。
- Xorbits 可以通过 GPU 加速运算,为分布式也做了很多优化,用户往往不需要知道其中的细节,就可以天然让他们的程序高效利用现有的算力了。
现有的解决方案
目前,已经有若干库和框架和 Xorbits 一样尝试解决这些问题。我们列出来其中几个主要成员。 它们都支持把数据处理和 AI 栈中最重要的工具 pandas 给分布式化。
Dask
Dask 是一个知名的 Python 框架,支持把 numpy、pandas、XGBoost 等框架用分布式方式加速。然而,Dask 的接口是延迟式的,也就是说,如果需要得到想要的数据,用户总是需要通过调用 .compute() 来触发执行,这样用起来会就会非常不方便。用户需要时常思考什么时候需要调用 .compute(),什么时候不需要。这需要相当程度上侵入他原先的代码。此外,Dask 也并不完全支持 pandas 的数据模型,它并不保证数据的顺序,所以用户在很多情况下并不能做到从 pandas 到 Dask 的无缝迁移。
Modin
Modin 宣称通过一行代码改动,可以加速 pandas 的执行。
不同于 Dask,Modin 不需要用户显式调用函数来触发执行,它是立即执行的。这对用户非常友好,不过这也意味着,立即执行使得优化的空间变得很小。试想下,用户做了a、b、c 3个操作,但只有 c 的结果是他需要的,这时候我们就可以利用优化技术例如列剪裁、谓词下推等,对中间过程 a 和 b 进行优化。立即执行意味着这样的优化几乎不可能。数据模型方面,Modin 支持 pandas 的数据模型,这点还是给用户提供了便利。
Modin 仅支持 pandas 接口,如果用户需要加速多维数组的计算、或者进行机器学习,Modin 就无能为力了。
Pandas API on Spark
Spark 是非常流行也非常成功的大数据框架,适合用来进行大规模数据清洗。Pandas API on Spark 在 Spark 3.2 版本引进,在此之前,它以 Koalas 的独立项目的方式发展了一段时间。
Pandas API on Spark 构建在 Spark 之上,因此继承了 Spark 的全部优缺点。其中一个优点是,Spark 相当成熟了,它有相当多的前人实践和教程可以参考。然而,Spark 是构建在 Java 生态之上的大数据系统,它很庞大很复杂,需要相当专业的团队来维护和真正跑起来,基于 Spark,一个想法从构建到真正实现到部署,需要不少代价。此外,如果用户代码出错,他或许能看到大量的错误栈充斥 Java 元素,这往往让 Python 用户无所适从。数据模型方面,Spark 并不保序,因此,像 shift 和 rolling 这些操作,pandas API on Spark 往往就失去了并行特性,然后回退到单机执行,因此这些时序相关的操作就完全无法利用到 Spark 的并行能力。
其他框架
其他还有许多框架试图解决加速的问题,包括 Vaex,还有近期较火的 polars 等等。他们要么就不够有名,要么就只支持单机,无法利用分布式的方式来处理大规模数据,因此相关对比我们以后再进行。
Xorbits 和现有方案对比
Xorbits 和现有方案相比,有这些特点:
- 完全和现有的接口兼容,不做任何修改。pandas、numpy 等等经过了这么多年的实践,用户接口禁得起推敲,我们没必要造新的轮子。
- 支持 pandas 的数据模型,用户的代码迁移必须是无痛的。
- 强力的执行性能,这点无需多谈,性能问题一直是重中之重。
- 充分利用加速硬件,如 GPU。
- 简单的部署,不需要复杂的领域知识。
我们把 Xorbits 和其他框架用一个表格进行横向对比。
| Dask | Modin | Pandas API on spark | Xorbits | |
|---|---|---|---|---|
| 接口兼容 | ❌ | ✅ | ✅ | ✅ |
| Pandas 数据模型 | ❌ | ✅ | ❌ | ✅ |
| GPU 支持 | ❌* | ❌ | ❌ | ✅ |
| Numpy 接口 | ✅ | ❌ | ❌ | ✅ |
| 不依赖 JVM | ✅ | ✅ | ❌ | ✅ |
* Dask GPU 的支持由 RAPIDS dask-cudf提供
为了测试 Xorbits 的性能,我们基于 TPC-H 基准测试,测试了 scale factor 100(大约100GB数据)和 1000(大约1TB数据)两个规模。TPC-H 之前主要用在 OLAP 应用领域,且只需要使用 pandas 接口中的一小部分就可以实现。但是,由于 TPC-H 使用非常广泛,用其他对比框架实现 TPC-H 并不困难,这给公平对比提供了可能。未来,我们会引入更多测试,以能真正利用到 pandas 接口的全部能力。
对于 TPC-H SF 100 测试,集群由一台 r6i.large 实例作为 supervisor,5台 r6i.4xlarge 实例作为 worker 组成。
TPC-H SF100:Xorbits vs. Dask

TPC-H SF100:Xorbits vs. Dask
综合所有查询,Xorbits 比 Dask 快7.3倍。Dask 在 Q21 跑的时候内存溢出,因此 Q21 被排除。
TPC-H SF100:Xorbits vs. Pandas API on Spark

TPC-H SF100::Xorbits vs. Pandas API on Spark
性能测试表明,Xorbits 和 Spark pandas 接口有着相似的性能,但是 Xorbits 提供更优秀的 API 兼容性。Pandas API on Spark 跑 Q1、Q4、Q7 和 Q21 查询时失败,跑 Q20 查询时内存溢出。
TPC-H SF100:Xorbits vs. Modin

TPC-H SF100:Xorbits vs. Modin
尽管 Modin 在大多数涉及数据重排的查询中内存溢出,显得性能差别没那么明显,Xorbits 依然比 Modin 快了3.2倍。
TPC-H SF1000:Xorbits
对于 TPC-H SF 1000 测试,集群由一台 r6i.large 实例作为 supervisor,16 台 r6i.8xlarge 实例作为 worker 组成。

TPC-H SF1000:Xorbits
Xorbits 能够跑通全部的测试,Dask、Pandas API on Spark 以及 Modin 大部分的测试都跑失败了。因此,我们无法对比性能的差别,我们计划未来在合适的时间继续对比。
Xorbits 未来开发计划
Xorbits 还相当年轻,但我们已经为它的未来做了长期规划。归纳来说,主要有:
- 未来 Xorbits 会将数据存储从 pandas 原生改成 arrow 原生,pandas 的内存表达存在一些问题,而使用 arrow 会有更优的表达,且对引擎更友好。
- 引入原生引擎,将向量化、代码生成技术等部分引入到 Xorbits,以支持更强大的性能。
- 加速尽可能多的数据处理和 AI 库,支持更多算法。
更多计划我们未来会详细披露,敬请期待。
总结
一行 pip install xorbits ,即刻尝试使用 Xorbits 吧。欢迎给我们任何反馈。
总的来说,Xorbits 是一个 Python 数据处理和 AI 的加速框架 ,它能加速许多知名 Python 库,包括 numpy、pandas、scikit-learn 等。Xorbits 利用多核和 GPU 来加速计算,支持单机加速,也可以轻松扩展到成千台机器,以支持处理 TB 级数据。根据我们的性能测试结果,Xorbits 跟其他知名分布式框架相比,是性能最好的。
关于未来速度
未来速度(Xprobe Inc.)成立的愿景之一是让大规模数据处理和 AI 触手可及。Xorbits 是我们的第一个开源产品。
我们有多个岗位正在招聘,如果对我们感兴趣,可以点击 招聘链接 应聘,亦可发送简历到 hr@xprobe.io。

