 Jon Wang
2023.07.11
Jon Wang
2023.07.11

我们非常激动地宣布 Xorbits Inference 正式与大家见面。
Xorbits Inference (Xinference) 是一个企业级分布式推理框架,用于完成大规模模型推理任务。Xinference 支持包括大语言模型 (LLM),多模态模型 (Multimodal models) 在内的各类模型。无论是 个人电脑 还是 分布式集群,通过 Xinference,你都可以轻松地体验最前沿的模型!在此基础上,通过 Xinference 提供 的 API 与第三方的集成接口,你还可以轻松地搭建起基于 AI 的谈话,写作,代码补全,图片生成等等应用。
背景
LLM 时代下,OpenAI 的 GPT-4,Google 的 PaLM 2 等模型在各行各业都展现出了非凡前景。更进一步的多模态模型更让人们看到了人类在 AI 加持下的无限可能。但对于许多公司和个人用于来说,OpenAI 等公司提供的服务可能并非最优解,这是因为:
- 数据隐私与安全问题:使用 AI 服务可能会造成企业或个人的数据泄漏。对个人来说,身份与行为信息在与 AI 的交互过程中可能发生泄漏。对企业来说这个问题更加严重,生产过程中所有调用 AI 服务的环节都可能会导致数据安全隐患。
- 定制需要:通用 AI 服务有些时候不是特定类型任务的最优解。大型企业往往需要基于自己的数据集对模型进行微调,来满足特定的任务。
- 成本:通用 AI 服务的价格相当高昂。而针对特定领域微调的小模型往往也能比较好地满足企业需要,这将大大降低模型的部署和推理成本。
而现在,开源社区日新月异。OpenLLaMA 等具备商业许可证的开源基础模型已经出现,基于这些基础模型微调的模型也在不断涌现。
因此,Xinference 的目标是以 简单的 API 提供生产级别的私有化模型大规模部署能力,从个人电脑到服务器集群,发挥异构硬件的全部潜力,达到 最极致的吞吐量 与 最低的推理延迟。
功能概述
🌟模型一键部署: Xinference 极致简化了包括大语言模型,多模态模型,语音识别模型等模型部署的过程。
⚡️内置最前沿的模型:你可以一键下载并部署 Xinference 中内置的大量前沿模型。包括 chatglm2,vicuna,
wizardlm 等等。我们拥有自己的 Hugging Face 账户,并会持续更新支持的模型列表。
🖥使用异构硬件:Xinference 可以使用 CPU 完成推理。也可以在显卡忙的时候把部分计算工作交给 CPU 完成,增大集群的吞吐率。
⚙️灵活的 API:Xinference 提供包括 RPC 和 RESTful API (兼容 OpenAI 协议) 在内的多种接口。你可以选择任意方式与已有系统进行集成。此外,Xinference 还提供命令行与 web UI 方便用户对系统进行管理和监控。
🌐 分布式架构:Xinference 使用分布式架构,让跨设备与跨服务器的模型部署成为可能。分布式架构还可以允许高并发推理,并让扩容和缩容更加简单。
🔌 第三方集成:Xinference 可以与包括 LangChain 在内的三方库无缝集成,协助快速构建基于 AI 的应用程序。
体验 Xinference
你可以通过 PyPI 安装 Xinference,我们强烈推荐使用一个新的虚拟环境来避免可能的依赖冲突:
$ pip install "xinference[all]"
xinference[all] 将会自动安装所有默认依赖,包括模型的运行时。我们也推荐根据硬件手动安装运行时,推高推理效率:
单机启动
$ xinference
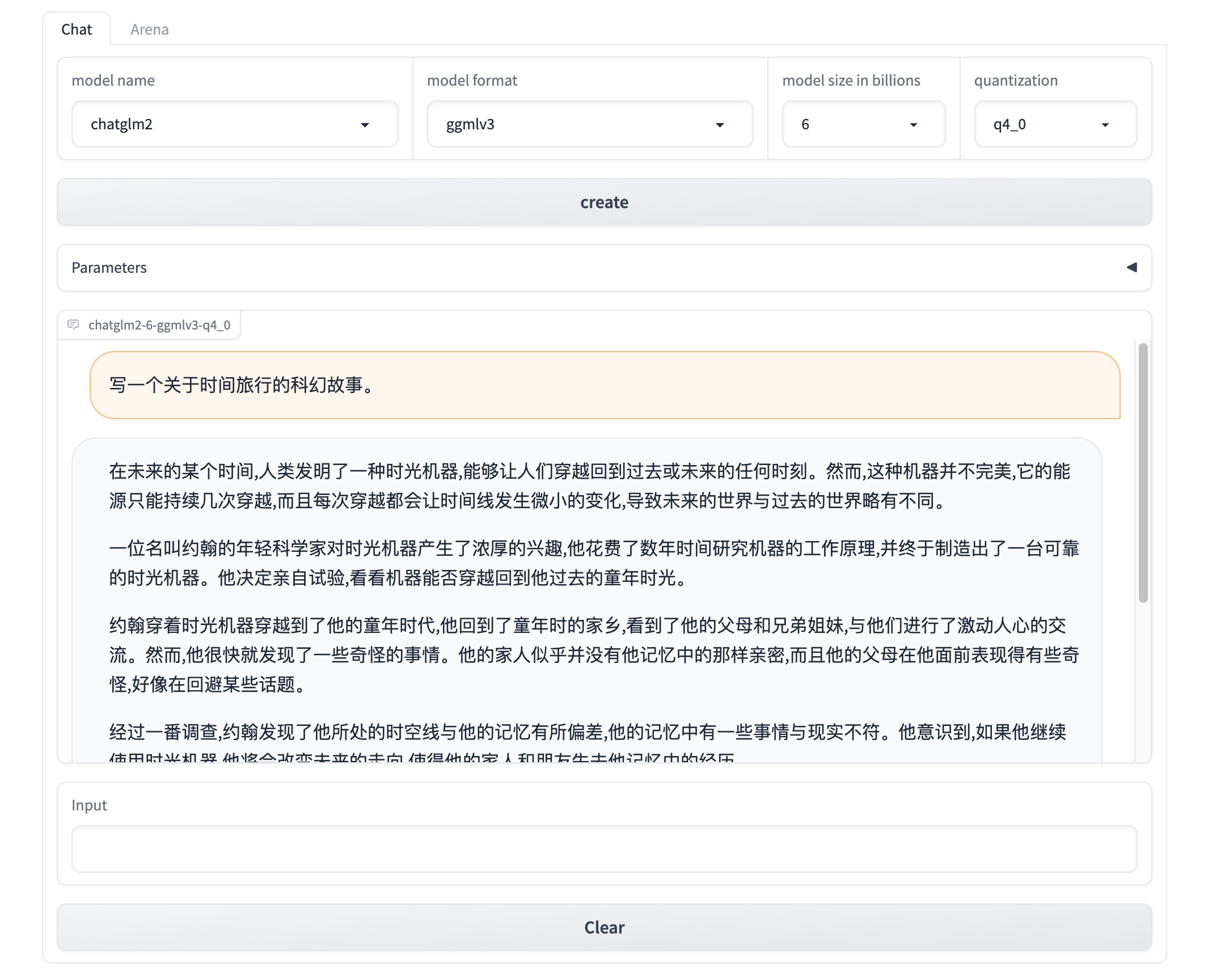
Xinference 启动后,会打印服务的 endpoint。通过这个 endpoint,你可以通过 CLI 或客户端来加载,查看,以及终止模型。 endpoint 同时还提供了一个 web UI 方便用户与任意模型互动。你甚至可以 同时与两个 LLM 对话来比较模型的好坏!
关于分布式部署此处不多展开,请参考 README。
内置模型
下面是目前 Xinference 支持的模型列表:
| Name | Type | Language | Format | Size (in billions) | Quantization |
|---|---|---|---|---|---|
| baichuan | Foundation Model | en, zh | ggmlv3 | 7 | ‘q2_K’, ‘q3_K_L’, … , ‘q6_K’, ‘q8_0’ |
| chatglm | SFT Model | en, zh | ggmlv3 | 6 | ‘q4_0’, ‘q4_1’, ‘q5_0’, ‘q5_1’, ‘q8_0’ |
| chatglm2 | SFT Model | en, zh | ggmlv3 | 6 | ‘q4_0’, ‘q4_1’, ‘q5_0’, ‘q5_1’, ‘q8_0’ |
| wizardlm-v1.0 | SFT Model | en | ggmlv3 | 7, 13, 33 | ‘q2_K’, ‘q3_K_L’, … , ‘q6_K’, ‘q8_0’ |
| vicuna-v1.3 | SFT Model | en | ggmlv3 | 7, 13 | ‘q2_K’, ‘q3_K_L’, … , ‘q6_K’, ‘q8_0’ |
| orca | SFT Model | en | ggmlv3 | 3, 7, 13 | ‘q4_0’, ‘q4_1’, ‘q5_0’, ‘q5_1’, ‘q8_0’ |
未来开发计划
Xinference 目前还在快速迭代过程中。我们会在近期从三个方面发力:
- 支持如 pytorch 的更多运行时,拥抱更广阔的生态。
- 优化模型调度与推理任务调度等核心功能,进一步提高吞吐并降低延迟。
- 加强第三方生态建设,与先有的 AI 基础设施更好地协作。
对于未来的开发计划,我们非常尊重并期待社区的反馈,欢迎广大用户和开发者提出宝贵意见。
总结
对于个人用户 Xinference 可以让你在个人电脑上体验最前沿的开源模型。而对于企业用户,Xinference 能够帮助你在计算集群上轻松地部署并管理模型,享受私有化部署带来的安全,定制化,以及低成本。
执行:
$ pip install "xinference[all]"
即刻尝试使用 Xinference 吧!

