 Peiyuan Liu
2023.07.21
Peiyuan Liu
2023.07.21

引言
在大型语言模型(LLMs)的训练中,文本数据集的去重起着至关重要的作用。它不仅可以提升训练的效率,同时也有效减轻隐私问题12。LLMs的发展依托于大规模且多样化的数据集,然而这些数据集往往包含大量从互联网爬取的重复序列,这无疑加剧了数据冗余和隐私风险34。文本去重不仅能加快LLMs的训练速度,同时也能降低数据记忆和隐私攻击的风险125。我们的创新在于采用Xorbits框架进行分布式的文本数据集去重。类似于Dask、Ray和Modin等框架一样,Xorbits能够在多台机器上实现大规模并行处理,从而提供更高的处理速度和更大的处理量。借助Xorbits进行文本数据集去重,我们能处理超出单机处理能力的大规模文本数据集,并且获得较高的效率,这无疑代表了LLMs数据处理的一项重大突破。
值得注意的是,Xorbits简化了数据科学和机器学习任务的扩展,覆盖了从数据预处理到模型服务的全过程。此外,它可充分利用多核或GPU,扩展到数千台机器,以处理太字节级别的数据或训练大型模型。Xorbits的高效去重接口dedup有效地填补了市场上的关键空白,提供了一种解决文本去重的优质API。其在单机和多机环境中的卓越性能,极大地方便了大规模文本去重,使Xorbits成为了那些需要去重大型语言数据集的用户的首选工具。
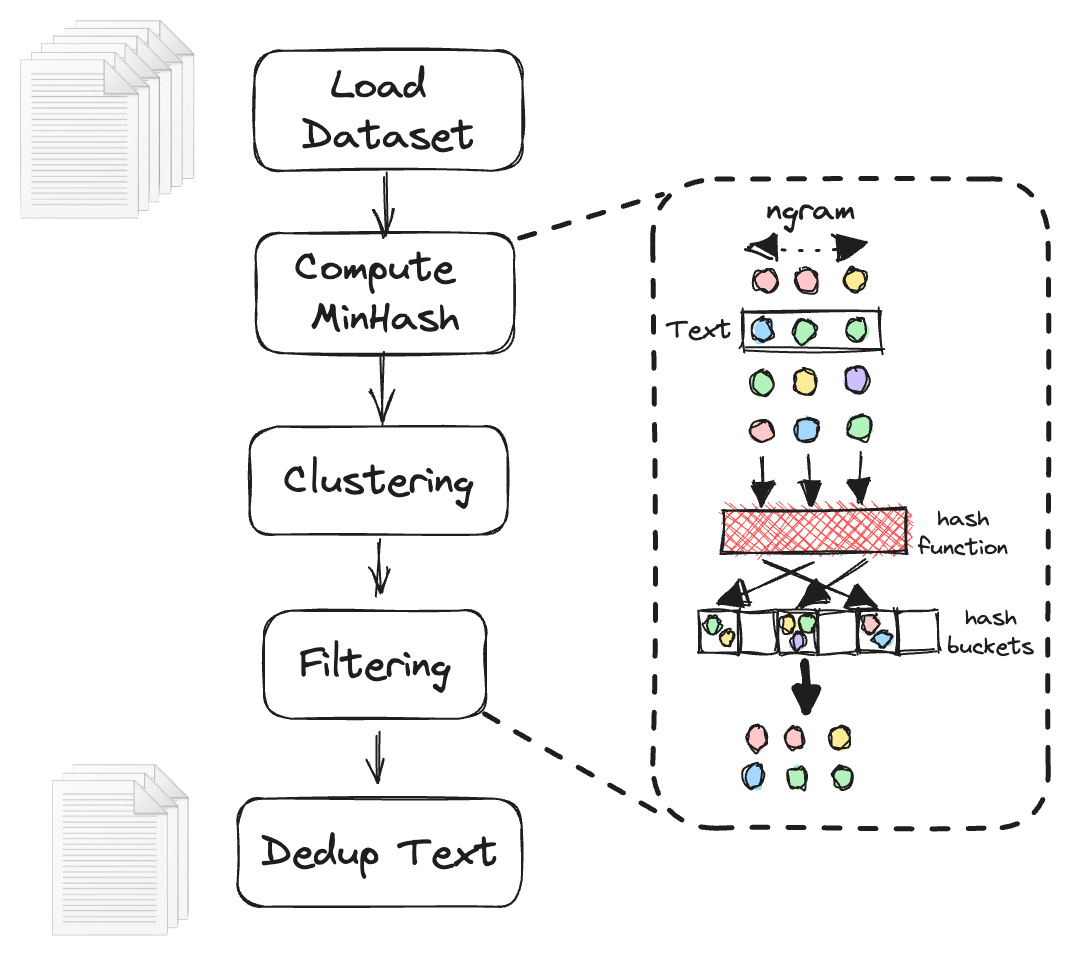
这是文本去重的基本流程图:
大型语言数据集与去重的挑战
在大型语言模型(LLMs)中,我们面临着处理如Oscar、BigCode等庞大语言数据集的挑战,这些数据集包含数十亿条记录。由于数据集的巨大规模,单机去重过程成为了一项困难的任务。
对这样的大型数据集,我们面临两方面的挑战:首先,单机的硬件限制使得将整个数据集加载到内存进行去重变得不可能;其次,即便数据集的大小在内存容量范围内,去重所需的计算开销可能非常大,导致处理时间过长。
Xorbits去重接口
为了解决上述问题,我们开发了Xorbits的去重接口。该接口利用分布式多节点机制来执行文本去重,通过此接口,我们能将数据集分割至多个节点进行并行处理。这样,我们不仅可以处理更大的数据集,还可以显著加速去重过程。
以下是Xorbits文本去重接口的简洁使用示例:
# 要安装xorbits,运行 `pip install xorbits`
import xorbits.pandas as pd
from xorbits.experimental import dedup
df = pd.DataFrame(...) # 假设df是你的文本数据集,且"text"列是需要去重的文本列
res = dedup(df, col="text")
有关更多功能参数,请参阅dedup文档。
以下是我们算法的详细步骤6:
-
我们给待去重的数据框(dataframe)添加一个唯一标识符列
__dedup_id。 - 我们采用如下的
embed_func函数来生成哈希值。该函数首先将文本内容分解为N-gram,然后应用哈希函数生成一系列签名__signatures,并将这些签名与相应的唯一标识符建立映射关系。每个签名都包含一个元组,元组中包含基于num_perm参数的文本行哈希值的位置信息。def embed_func( row: pd.Series, *, text: str, num_perm: int, ngram_size: int, min_length: int, hashranges: List[Tuple[int, int]], permutations: np.ndarray, ) -> pd.Series: content, idx = row[text], row["__dedup_id"] a, b = permutations masks: np.ndarray = np.full(shape=num_perm, dtype=np.uint64, fill_value=MAX_HASH) tokens: Set[str] = { " ".join(t) for t in ngrams(NON_ALPHA.split(content), ngram_size, min_length) } hashvalues: np.ndarray = np.array( [sha1_hash(token.lower().encode("utf-8")) for token in tokens], dtype=np.uint64 ) permuted_hashvalues = np.bitwise_and( ((hashvalues * np.tile(a, (len(hashvalues), 1)).T).T + b) % MERSENNE_PRIME, MAX_HASH, ) hashvalues = np.vstack([permuted_hashvalues, masks]).min(axis=0) Hs = [ (i, bytes(hashvalues[start:end].byteswap().data)) for i, (start, end) in enumerate(hashranges) ] return pd.Series({"__signatures": Hs, "__id": idx}) - 利用这个嵌入函数,我们采用apply操作对数据框进行嵌入计算。
embedded = in_df_with_id.apply( embed_func, axis=1, output_type="dataframe", dtypes=pd.Series(["object", "bytes"], index=["__signatures","__id"]), ) - 我们利用局部敏感哈希(LSH)方法,通过将高维数据映射到降维空间来实现近似最近邻搜索。此处,我们需要将
__signatures列“展开(explode)”以获取每个文本切片的位置信息。然后,我们对其进行分组并设定集群哈希值。clusters = ( embedded.explode("__signatures") .groupby("__signatures", sort=False)["__id"] .apply(set) ) - 然后我们构建并查集(Union Find)。所有先前的数据框操作都可以在各节点并行执行,每个节点都可以计算其并集。然而,去重需要全局并查集,这就需要我们在计算后合并所有集合。由于这是去重算法中唯一不能并行化的步骤,我们采用了基于Cython的并查集来加速计算。
for cluster in clusters: if len(cluster) <= 1: continue idx = min(cluster) for x in cluster: op.union_find.union_(x, idx) - 在全局并查集构建完成后,我们使用
dataframe.map对原始文本进行去重,同时在去重完成后舍弃签名列__dedup_id。res = input_data[ input_data["__dedup_id"].map(lambda x: op.union_find.find(x) == x) ].drop(columns="__dedup_id")
以下的动画精准地概括了上述步骤:

基准测试
我们在”Oscar2201”的中文数据集上进行了精细的算法测试。测试运行在AWS的r5a.16xlarge 机器上,该机器具有64个核心和512GB的内存。测试结果如下:
| 数据集大小 | 去重前的行数 | 去重后的行数 | 时间 |
|---|---|---|---|
| 1GB | 68,000 | 62,250 | 50s |
| 10GB | 666,000 | 559,420 | 172s |
| 50GB | 3,120,337 | 2,387,421 | 572s |
| 100GB | 6,292,027 | 4,603,959 | 1,073s |
我们进一步在相同的数据集上进行了分布式测试。这次,我们使用了AWS的r6i.8xlarge机器,具有32个核心和256GB的内存。结果如下:
| 数据集大小 | 去重前/后的行数 | 节点数 | 时间 |
|---|---|---|---|
| 500GB | 31,385,092 / 20,380,655 | 5 | 1,174s |
| 500GB | - Same - | 7 | 938s |
| 500GB | - Same - | 10 | 683s |
| 500GB | - Same - | 15 | 550s |
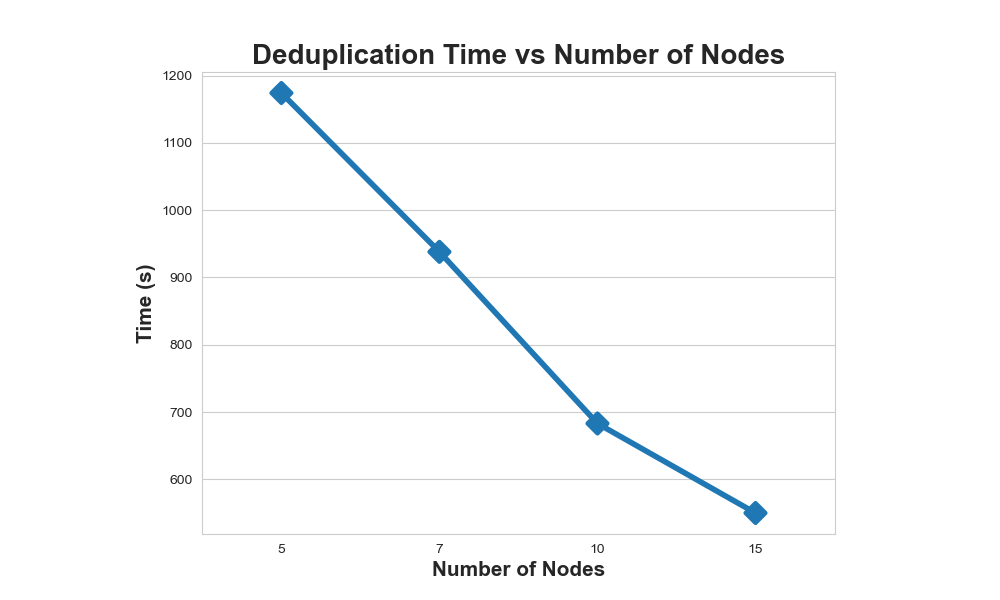
结果显示了Xorbits去重速度的强大,以及它能够随着节点数量的增加而适应的能力。尽管如此,我们在节点数从10增加到15时,观察到性能提升的速度有所减缓。这种轻微的减速可能归因于合并每个数据块的并查集所带来的内在算法挑战。这项基于MinHash的操作在全局范围内是必要的,但在分布式设置中执行并不可行,因此在大节点数时给时间减少设置了上限。
值得注意的是,借助Xorbits利用多节点的能力是一项相对直接的任务。对于那些对实施此类解决方案感兴趣的人,我们提供了一份详尽的指南,链接如下:集群部署。
未来展望
在我们的现有架构中,去重需要在本地或云端存储并通过xorbits.pandas.read_csv或read_parquet方法读取数据集。尽管当前的运行状况良好,但我们一直寻求进一步提升用户体验和性能。我们欣然宣布,我们正在与Hugging Face的datasets——一个针对大规模机器学习数据集的强大库进行集成,以简化和加速数据读取流程。我们的目标不止于此,我们计划将我们的文本特征提取技术扩展到n-grams之外,包括诸如TF-IDF等方法。此外,我们计划引入更多哈希方法,如SimHash,以进一步提升我们的去重工作流的灵活性和效率。
结论
随着文本数据集规模的迅速扩大,可扩展的文本去重已经变得至关重要。Xorbits成功地通过其简易且高效的dedup接口,填补了这一关键空白。该接口能够实现大规模数据集的单节点多核以及多节点多核去重,进而克服了单机器性能的限制。我们热切地建议需要高效且有效文本去重方案的用户采用Xorbits,这是数据科学家和机器学习工程师必不可少的工具。
Reference
1: Nikhil Kandpal, Eric Wallace, Colin Raffel, Deduplicating Training Data Mitigates Privacy Risks in Language Models, 2022
2: Katherine Lee, Daphne Ippolito, et al., Deduplicating Training Data Makes Language Models Better, 2022
3: Abadji Julien, Ortiz Suarez Pedro, et al. Towards a Cleaner Document-Oriented Multilingual Crawled Corpus, 2022
4: Bharat Ramanathan, Processing Data for Large Language Models, 2022
5: Gowthami Somepalli, et al., Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models, 2022

