 Dabai Wang
2023.05.31
Dabai Wang
2023.05.31

介绍
本文详细介绍了 Pandas rolling 相关性函数的瓶颈,并提出了我们解决该问题的方法。
rolling().agg('corr') 是一种非常强大的 Pandas 函数,可在 DataFrame 或 Series 上执行。
然而,我们发现当处理拥有大量列的 DataFrame 时,DataFrame.rolling().agg('corr') 函数非常慢。
即使这个 DataFrame 行数为 0,执行 rolling().agg('corr') 函数也需要很长时间。
更多细节描述请参见 Xorbits/issues。
本文分析了 DataFrame.rolling(window=30).agg('corr') 在不同输入形状下的性能影响,并利用 py-spy 模块生成火焰图可视化不同函数的时间消耗,进而找出解决问题的方法。
本文的研究成果有望为使用 Pandas rolling().agg('corr') 函数的开发者提供有用的参考,提高其性能表现和计算效率。
性能测试
本次测试选择了 Huge Stock Market Dataset
作为测试数据,该数据集记录了所有美国股票和 ETF 的历史日价格和交易量。
我们从中选取了 1000 只股票的收益率,并生成了 CSV 文件 returns.csv。
该文件可用于测试 Pandas rolling().agg('corr') 函数的性能表现。
bac_i.us glt.us ... atu.us jhy.us xco.us mik.us apf.us
2015-01-01 NaN NaN ... NaN NaN NaN NaN NaN
2015-01-02 NaN NaN ... NaN NaN NaN NaN NaN
2015-01-03 0.000000 0.000000 ... 0.000000 NaN 0.000000 0.000000 0.000000
2015-01-04 0.000000 0.000000 ... 0.000000 NaN 0.000000 0.000000 0.000000
2015-01-05 -0.003401 -0.034154 ... -0.032051 NaN -0.038278 -0.039271 -0.004082
... ... ... ... ... ... ... ... ...
2015-12-27 0.000000 0.000000 ... 0.000000 0.000000 0.000000 0.000000 0.000000
2015-12-28 0.005668 -0.023806 ... -0.016163 0.005981 0.035398 0.008692 -0.001392
2015-12-29 0.003322 0.024944 ... 0.017664 -0.007005 0.025641 0.006349 -0.001467
2015-12-30 -0.002976 -0.015136 ... -0.019380 0.001269 -0.100000 -0.004056 -0.004041
2015-12-31 -0.001493 -0.023771 ... -0.014771 -0.008246 0.148148 0.000452 0.009147
[365 rows x 1000 columns]
数据集 (365, 1000)
import pandas as pd
import time
return_matrix = pd.read_csv("/path/to/returns.csv", index_col=0, parse_dates=True)
roll = return_matrix.rolling(window=30).agg('corr')
Execution time: 105.7209062576294
水平一半数据集 (182, 1000)
import pandas as pd
import time
return_matrix = pd.read_csv("/path/to/returns.csv", index_col=0, parse_dates=True)
return_matrix = return_matrix.iloc[: len(return_matrix) // 2]
roll = return_matrix.rolling(window=30).agg('corr')
Execution time: 97.95154094696045
垂直一半数据集 (365, 500)
import pandas as pd
import time
return_matrix = pd.read_csv("/path/to/returns.csv", index_col=0, parse_dates=True)
return_matrix = return_matrix[return_matrix.columns[: 500]]
roll = return_matrix.rolling(window=30).agg('corr')
Execution time: 26.112659215927124
空行数据集 (0, 1000)
import pandas as pd
import time
return_matrix = pd.read_csv("/path/to/returns.csv", index_col=0, parse_dates=True)
return_matrix = return_matrix.drop(return_matrix.index)
roll = return_matrix.rolling(window=30).agg('corr')
Execution time: 89.09344792366028
以上实验结果表明,在 DataFrame 或 Series 上执行 rolling().agg('corr') 操作的执行时间很大程度上取决于列数,而不是行数。
使用 py-spy 包来可视化不同模块的时间消耗,具体如下:
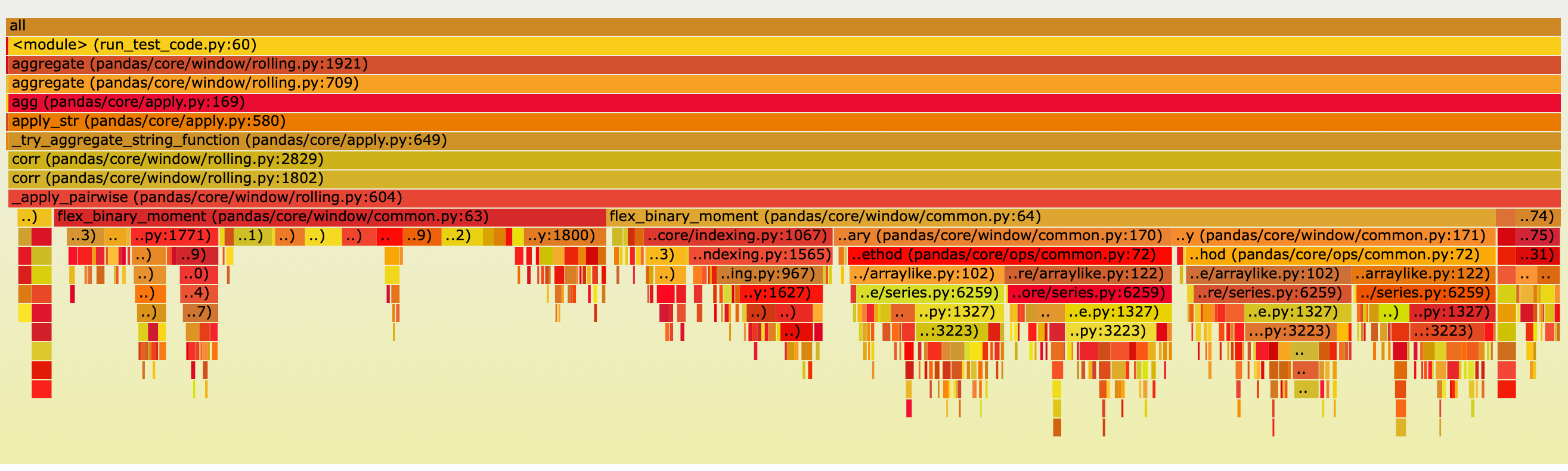
主要的执行时间集中在以下模块: function
def flex_binary_moment(arg1, arg2, f, pairwise=False):
results = defaultdict(dict)
for i in range(len(arg1.columns)):
for j in range(len(arg2.columns)):
if j < i and arg2 is arg1:
# Symmetric case
results[i][j] = results[j][i]
else:
results[i][j] = f(
*prep_binary(arg1.iloc[:, i], arg2.iloc[:, j])
)
flex_binary_moment 被用于计算每两列之间的 rolling 相关性。
results[i][j] 代表第i列和第j列之间的 rolling 相关性。
两个耗时的部分是 f() (35.5%) 和 prep_binary (57.2%).
f() 计算 rolling 相关性,而 prep_binary 则将包含NaN值的行在两列中进行了掩蔽。
读者可能对此有疑问,为什么计算 rolling 相关性所花费的时间比 prep_binary 更短。下面让我们看一下这两个部分的代码。
prep_binary
def prep_binary(arg1, arg2):
# mask out values, this also makes a common index...
X = arg1 + 0 * arg2
Y = arg2 + 0 * arg1
return X, Y
这是 prep_binary 执行的火焰图,显示了大量的时间花费在计算 X 和 Y 上。
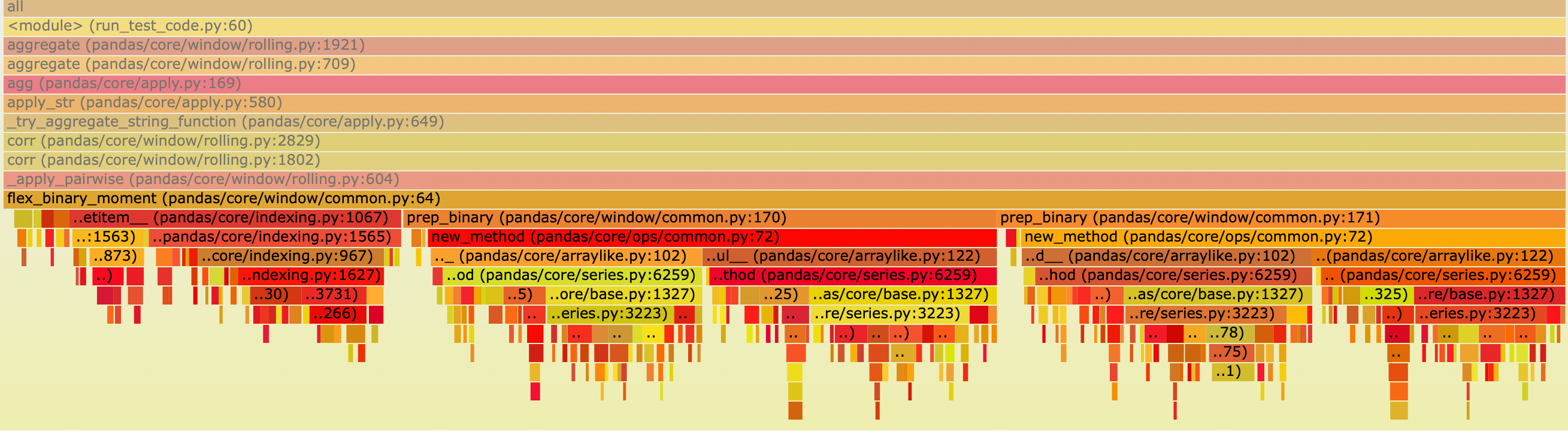
rolling correlation
def corr_func(x, y):
x_array = self._prep_values(x)
y_array = self._prep_values(y)
window_indexer = self._get_window_indexer()
min_periods = (
self.min_periods
if self.min_periods is not None
else window_indexer.window_size
)
start, end = window_indexer.get_window_bounds(
num_values=len(x_array),
min_periods=min_periods,
center=self.center,
closed=self.closed,
step=self.step,
)
self._check_window_bounds(start, end, len(x_array))
with np.errstate(all="ignore"):
mean_x_y = window_aggregations.roll_mean(
x_array * y_array, start, end, min_periods
)
mean_x = window_aggregations.roll_mean(x_array, start, end, min_periods)
mean_y = window_aggregations.roll_mean(y_array, start, end, min_periods)
count_x_y = window_aggregations.roll_sum(
notna(x_array + y_array).astype(np.float64), start, end, 0
)
x_var = window_aggregations.roll_var(
x_array, start, end, min_periods, ddof
)
y_var = window_aggregations.roll_var(
y_array, start, end, min_periods, ddof
)
numerator = (mean_x_y - mean_x * mean_y) * (
count_x_y / (count_x_y - ddof)
)
denominator = (x_var * y_var) ** 0.5
result = numerator / denominator
return Series(result, index=x.index, name=x.name)
关键在于 Pandas 将 x_array 和 y_array 转换为 NumPy 数组,以供 Cython 例程使用。而 NumPy 的计算速度要比 DataFrame 速度快很多。
x_array = _prep_values(x)
y_array = _prep_values(y)
解决方案
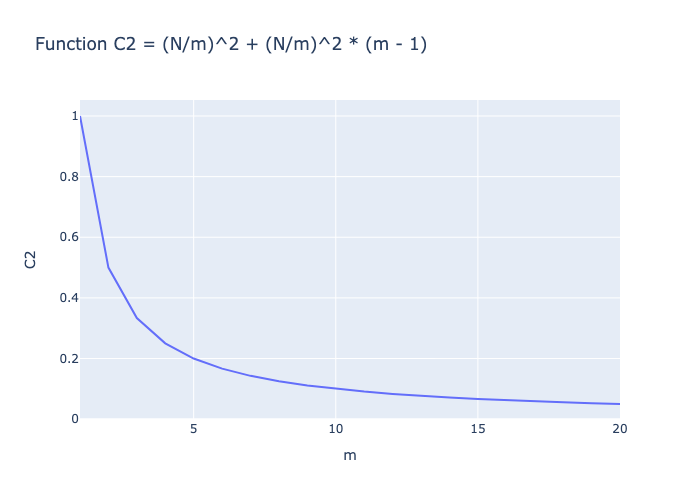
本文从并行计算的角度提出了一种简单的优化方法,正如之前分析的,显著减少列的数量有助于减少计算时间。 假设有一个形状为(365,N)的 DataFrame,并行度为 m,则可以生成 m 个形状为(365,N/m)的 Sub-DataFrames。 并行度可以设置为处理器的核心数。为简化过程,在计算之前忽略不同核心之间的通信时间,并将原始 DataFrame 广播到每个核心。
在不添加任何并行策略的情况下,计算复杂度为:
C_1 = N^2
使用并行策略,由于每个核心可以同时操作,因此计算次数为:
C_2 = (N/m)^2 + (N/m)^2 * (m - 1)
在 C2 中,第一项是当前 Sub-DataFrames 所需的计算量,第二项是当前 Sub-DataFrames 和其他 Sub-DataFrames 所需的计算量。 如图所示,在并行化后,计算量得到了减少。 下图说明了当m增加时计算复杂度的变化情况。
总结
本文分析了与 DataFrame.rolling().agg('corr') 相关的性能问题,并利用 py-spy 模块生成了一个火焰图来可视化各个模块的时间消耗。
揭示了性能问题的根本原因是 prep_binary 函数中两个数组的索引对齐操作。此外,还从并行的角度提出了一个简单的优化方法。
希望本研究能够为专注于优化 Pandas 大规模数据计算的开发人员提供帮助。

