 Dreamsome
2024.01.30
Dreamsome
2024.01.30

Text-to-SQL,也就是将文本转化为结构化查询语言(SQL),是一种将自然语言式的数据库问题转换为能在关系型数据库中执行的结构化查询语句的过程。 这项技术在大型语言模型(LLM)取得广泛关注之前,就已经是自然语言处理(NLP)领域研究的核心话题,因为长期以来,编写数据库查询始终是一个困扰人们的难题。
首先,编写一条无误的SQL语句本身就并非易事。数据库系统经常需要保存大量数据,这意味着在查找符合某种特征的数据的过程中,我们需要结合复杂的过滤和排序技术。其次,数据库中的各个表格之间存在错综复杂的依赖关系,用户在进行多表查询时,必须学会使用复杂的关系模型和嵌套语法。
此外,现代数据库包含了不同的分支,针对不同的场景,它们各自演化出了自己的解决方案。数据库技术中的新功能和优化需要持续学习和适应, 这对于经验丰富的程序员来说也是一个挑战,尤其是当他们想要针对某个数据库写出高效的SQL语句时,往往需要反复调试,这无疑会消耗大量的精力和时间。

本文将介绍如何基于 Chat2DB 和 Xinference 打造一个完全本地、端到端的 Text2SQL 方案,使用 Chat2DB 作为查询数据的界面, 使用开源的 Qwen-Chat 14B 作为 AIGC 的核心组件——LLM。
什么是 Chat2DB?
Chat2DB 是一款开源免费的多数据库客户端工具。 它支持在 Windows 和 Mac 上进行本地安装,同时也可用于服务器端部署以及通过网页访问。Chat2DB UI 设计简洁,但功能强大,与传统的数据库客户端软件相比, 其 AIGC 能力能够将自然语言转换为 SQL,也可以将 SQL 转换为自然语言,可以给出研发人员 SQL 的优化建议,极大的提升人员的效率,是AI时代数据库研发人员的利器,不仅数据库开发人员可以用,不懂 SQL 的运营和业务人员也可以用它快速查询业务数据,生成报表。

什么是 Xinference?
Xinference 是一个开源模型推理平台,支持大型语言模型(LLM)、嵌入式模型和 ReRank 模型等在内的多种 AI 模型。 它提供与 OpenAI API 兼容的 API,并且能够轻松适配第三方开发者工具,如 LangChain、LlamaIndex 和 Dify ,便于模型的集成和开发。Xinference 内置了多种推理引擎,可以在服务器和个人设备上部署模型。 Xinference 还支持分布式多机、多卡模型推理,能够在多个设备或机器间高效分配模型推理任务,满足高可用的部署需要。
1.安装 Xinference
1.1 服务器
如果你的目标是在一台 Linux 或者 Window 服务器上部署大模型,可以使用 Xinference 官方的 Docker 镜像来一键安装和启动 Xinference 服务 (确保你的机器上已经安装了 Docker 和 CUDA),命令如下:
docker run -p 9997:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0
启动后,我们可以通过机器的 9997 端口来访问 Xinference 服务。
1.2 个人设备
如果你想在自己的 Mac 或者个人电脑上部署大模型,可以通过以下命令来安装 Xinference:
pip install xinference[ggml]
安装后只需要输入 xinference-local(默认端口 9997),就可以在你的 Mac 上启动 Xinference 服务。
2.部署 Qwen-14B 模型
2.1 Web UI 方式启动模型
Xinference 启动之后,在浏览器中输入: http://<XINFERENCE_HOST>:<XINFERENCE_PORT>,我们可以打开 Xinference 的 Web UI。然后进入“Launch Model”标签,搜索到 qwen-chat,
选择模型启动的相关参数,然后点击模型卡片左下方的小火箭 🚀 按钮,就可以部署该模型到 Xinference。默认 Model UID 是 qwen-chat(后续通过将通过这个 ID 来访问模型)。

当你第一次启动 Qwen 模型时,Xinference 会从 HuggingFace 下载模型参数,大概需要几分钟的时间。Xinference 将模型文件缓存在本地,这样之后启动时就不需要重新下载了。 Xinference 还支持从其他模型站点下载模型文件,例如 modelscope。
2.2 命令行方式启动模型
我们也可以使用 Xinference 的命令行工具来启动模型,默认 Model UID 是 qwen-chat(后续通过将通过这个 ID 来访问模型):
xinference launch --model-name qwen-chat \
--size-in-billions 14 \
--model-format pytorch \
--endpoint "http://<XINFERENCE_HOST>:<XINFERENCE_PORT>" \
除了 WebUI 和命令行工具, Xinference 还提供了 Python SDK 和 RESTful API 等多种交互方式, 更多用法可以参考 Xinference 官方文档。
3. 安装和部署 Chat2DB,并接入模型
在上一部分中,我们利用 Xinference 提供的模型服务在本地成功部署了大型语言模型(LLM)——Qwen。接下来,我们安装和部署 Chat2DB,并且接入我们刚刚部署好的 Qwen 模型。
3.1 Docker 安装
下面是参考 Chat2DB 官方文档用 Docker 启动的命令:
docker run --name=chat2db -ti -p 10824:10824 -v <LOCAL_PATH>:/root/.chat2db chat2db/chat2db:latest
启动容器后,打开 localhost:10824 就能看到 Chat2DB 的 Web UI。
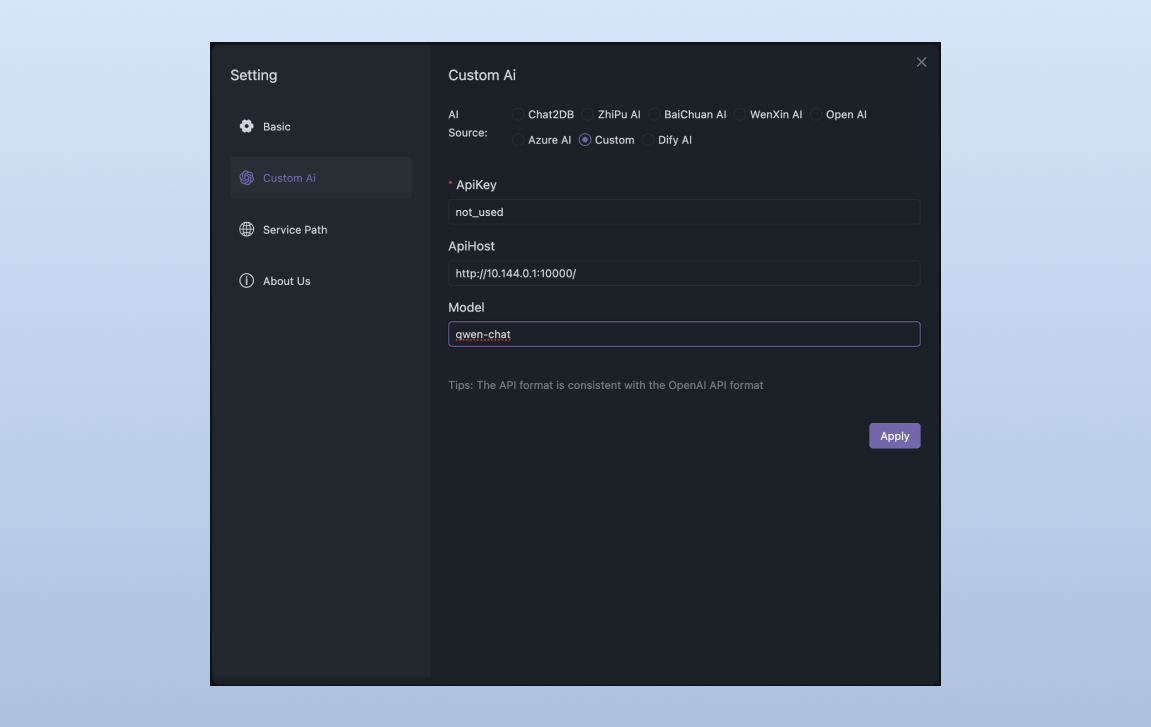
3.2 Custom AI 配置
在 Chat2DB 设置界面进行 AI 来源配置,其中 Api Host 输入 Xinference 服务的地址 ip:端口,模型名填写 qwen-chat (也就是模型 ID):
4. 通过 Chat2DB 实现数据库查询
首先我们需要在 Chat2DB 中创建一个数据库连接(这里我选的是 PostgreSQL)。创建成功后,我们打开一个 Console。在 Console 中,我们即可以在编辑器中直接写 SQL 也可以通过编辑器顶部的输入框,输入自然语言, 让 LLM 自动生成 SQL。
首先,我们让 AI 来创建一张 product 表,并且 mock 10 条数据进行测试。可以看到 Chat2DB 创建了相应的 DDL 语句,以及专门插入数据的 SQL 语句。
在成功执行之后,我又通过 Chat2DB 生成了一条“查找某类产品中价格最便宜的三个产品”的 SQL,可以看到 Chat2DB 不仅生成了相应的 SQL 语句,而且可以成功运行。
除了生成 SQL 之外,Chat2DB 还同时提供了“解释 SQL”的功能,这里我让它解释了一条分组聚合的 SQL,解释得非常详细,这无疑可以帮助我们快速理解团队中其他小伙伴写的复杂 SQL,从而节省很多时间。除此之外,Chat2DB 还提供将 SQL 方言互转的功能,感兴趣的小伙伴可以自行探索。

总结
本文详解了如何结合 Chat2DB 和 Xinference,通过运用大型语言模型 Qwen-Chat 14B,实现从文本到 SQL 的自动转换,使得数据库查询过程更加便捷和高效。 步骤包括安装和部署 Xinference,启动 Qwen-Chat 14B 模型,以及在 Chat2DB 上进行数据库查询等。这种新的查询方式将有望改变数据库查询的传统模式, 大大提高数据库查询效率,降低门槛。

