 Kaisheng He
2023.03.21
Kaisheng He
2023.03.21

Pandas 要更新大版本了! 回顾下 Pandas 的历史,它从诞生时的 0.1 到 1.0 花了超过十年的时间,在 2020 年正式发布 1.0 后,三年后再次迎来了大的更新。 如果说 1.0 发布意味着 Pandas DataFrame API 已经趋于稳定,那么从最新的 release notes 可以看到,Pandas 2.0 是一场关于性能的革命, 这不禁让人想到 Python 之父 Guido 对 Python 的规划,一系列 PEP 也都是关于性能优化的,整个 Python 社区都在这方面发力。
Arrow backend
Apache Arrow 是一个统一的内存存储格式,与 Arrow 的集成是 2.0 中最引人注意的特性。在引入 Arrow 之前,Pandas 数据在内存中绝大部分都是以 Numpy array 的形式存在,每一列数据都以向量的形式存储,内部用 BlockManager 去管理这些向量。但是 Numpy 本身并不是为 DataFrame 这样的数据结构而设计,对于一些数据类型支持并不是很好,比如字符串类型、缺失值等。早在 2013 年,Pandas 的作者 Wes McKinney 就有一个很著名的 talk 叫做 “10 Things I Hate About Pandas”,这其中大部分都是关于性能的,有些到现在都很难解决。 在提出这些问题的四年后,也就是 2017 年,Wes McKinney 作为 co-founder 发起了 Apache Arrow 这个项目,所以这也是为什么 Arrow 的集成会成为最引人注意的特性,因为它在设计上就与 Pandas 非常契合。那我们看下 Arrow 的集成给 Pandas 带来了哪些提升。
缺失值
许多用过 Pandas 的用户都会经历过列的类型从整数型变成了浮点数型,因为在原始数据或者计算过程中,这一列引入了缺失值,Pandas 内部会自动将这一列的类型转成浮点数。
In [1]: pd.Series([1, 2, 3, None])
Out[1]:
0 1.0
1 2.0
2 3.0
3 NaN
dtype: float64
2.0 之前,在 Pandas 内部,对于不同类型的缺失值都有不同的表示。比如 np.nan 用来表示浮点数的缺失值,None 或者 np.nan 表示
object 类型的缺失值,日期相关的缺失值则用 pd.NaT 表示,而在 Pandas 1.0 中,pd.NA 可以用来表示整数和布尔类型的缺失值,不过需要用户手动指定。可以看出来,在这方面,Pandas 一直想改进,但是却很挣扎。Arrow 的引入可以完美地解决问题,不需要 Pandas 内部对每一种类型都一套实现,更契合的内存数据结构省了很多麻烦。目前 Pandas 2.0 可以手动指定类型为 pyarrow。
In [1]: df2 = pd.DataFrame({'a':[1,2,3, None]}, dtype='int64[pyarrow]')
In [2]: df2.dtypes
Out[2]:
a int64[pyarrow]
dtype: object
In [3]: df2
Out[3]:
a
0 1
1 2
2 3
3 <NA>
字符串类型
低效的字符串类型也是 Pandas 经常被诟病的地方,前面也说到,Pandas 之前内部是使用 Numpy 来表示数据,但是 Numpy 并不是用来做字符串的处理,它更多是数值类型的计算,所以在 Pandas 内部,一列字符串类型的数据其实就是一组 PyObject 的指针,真正的数据都分散在整个进程堆里,这无疑使得内存消耗变多并且不可预测,Pandas 处理数据时,你需要差不多是原数据 5 到 10 倍的内存才能够比较顺畅,这个问题在数据越来越多的今天,显得越来越严重。
当然,Pandas 在 1.0 时就尝试解决过这个问题,通过 Pandas 扩展类型支持了实验性质的 StringDtype,其实就是用 Arrow string 作为扩展类型,也是为 2.0 的全面支持做了铺垫。Arrow 作为一种列式存储,数据在内存里是连续的,包括字符串。当你在读取一整个字符串列的时候,
不需要通过指针再找到对应的数据,不会遇到读取过程中各种 cache miss,这些在内存使用和计算上都会带来显著提升。
In [1]: import pandas as pd
In [2]: pd.__version__
Out[2]: '2.0.0rc1'
In [3]: df = pd.read_csv('pd_test.csv')
In [4]: df.dtypes
Out[4]:
name object
address object
number int64
dtype: object
In [5]: df.memory_usage(deep=True).sum()
Out[5]: 17898876
In [6]: df_arrow = pd.read_csv('pd_test.csv', dtype_backend="pyarrow", engine="pyarrow")
In [7]: df_arrow.dtypes
Out[7]:
name string[pyarrow]
address string[pyarrow]
number int64[pyarrow]
dtype: object
In [8]: df_arrow.memory_usage(deep=True).sum()
Out[8]: 7298876
可以看到,一个不算大的 DataFrame,使用默认行为读取的时候,统计使用的内存为 17M,而指定 Arrow 之后,内存占用只有不到 7M,更大规模上的优势会更加明显。除了内存,我们再看下计算性能。
In [9]: %time df.name.str.startswith('Mark').sum()
CPU times: user 21.1 ms, sys: 1.1 ms, total: 22.2 ms
Wall time: 21.3 ms
Out[9]: 687
In [10]: %time df_arrow.name.str.startswith('Mark').sum()
CPU times: user 2.56 ms, sys: 1.13 ms, total: 3.68 ms
Wall time: 2.5 ms
Out[10]: 687
统计所有名字叫 Mark 的人的个数,默认 Pandas 的计算需要的时间差不多是 Arrow 的 10 倍,这是一个让人兴奋的结果,更高效的内存排布给计算带来的收益更大,这一点足以让人对 Pandas 2.0 充满了期待。
Copy-on-Write
Copy on write (CoW) 其实是计算机领域经常用到的一个优化手段,简单来说,就是有多个调用者同时请求同一个资源时,不会每个调用者都拷贝,而只是持有一个指向该资源的指针,直到有调用者对其修改时,才会真正拷贝数据,保证其他调用者看到的还是原本不变的资源。
那这个 CoW 跟 Pandas 有什么关系呢,其实引入这个机制不仅仅是为了提高性能,更多考虑的是易用性。如果经常写 Pandas 的用户,常会在代码里看到 copy 函数,也就是对某个中间结果拷贝,我甚至见过每一步都调用 copy 的代码,这种情况的出现其实跟 Pandas 本身行为有关。 Pandas 函数调用返回的数据分为两种类型,一种是 copy,也就是为返回的 DataFrame 分配了新的内存,跟传入的 DataFrame 是不共享的, 还有一种是 view,返回的 DataFrame 与传入的 DataFrame 共享一份数据,view 的改动会导致原 DataFrame 也改动。一般索引操作会返回 view, 但也有例外,即使你声称是一名 Pandas 专家,也有可能在这里写出错误的代码,所以手动调用 copy 成为了保险的选择。
In [1]: df = pd.DataFrame({"foo": [1, 2, 3], "bar": [4, 5, 6]})
In [2]: subset = df["foo"]
In [3]: subset.iloc[0] = 100
In [4]: df
Out[4]:
foo bar
0 100 4
1 2 5
2 3 6
在上面的代码里,subset 返回的就是 view,而当你去给 subset 设置一个新的值的时候,原始的 df 的值也改变了,如果没有意识到这一点,
后面所有关于 df 的计算可能都会有很大的偏差。为了避免 view 带来的问题,Pandas 中又存在一些函数,在计算时内部强制 copy,
比如 set_index, reset_index, add_prefix 等等,这又导致了性能问题。那我们看下在引入 CoW 策略下的行为:
In [5]: pd.options.mode.copy_on_write = True
In [6]: df = pd.DataFrame({"foo": [1, 2, 3], "bar": [4, 5, 6]})
In [7]: subset = df["foo"]
In [7]: subset.iloc[0] = 100
In [8]: df
Out[8]:
foo bar
0 1 4
1 2 5
2 3 6
在打开 copy_on_write 之后,subset 改写数据触发了拷贝,数据修改只影响 subset 本身,df 的数据还是不变。
这时候的行为更加符合直觉,也让一些函数可以更加大胆的做一些 in-place 的操作,避免拷贝带来的开销。关于 CoW 更详细的解释,
Pandas 文档给了非常详细的说明,
总之,用户可以放心使用索引操作,不必担心影响到原来的数据。不得不说,这个特性系统性地解决了略显混乱的索引操作,
同时也给很多算子带来了非常大的性能提升。
One more thing
当我们再仔细去看 Wes McKinney 的 talk,我们会发现,当年所说的 “10 Things I Hate About Pandas” 其实是有11个问题,其中最后一个是 “No multicore/distributed algos”。

Pandas 社区目前选择了在单机上先做好,至少目前看来,这方面 Pandas 完全值得信任,Arrow 的引入使得像 Polars 这样的竞品优势将不复存在。 而在分布式方面,Python 社区也一直在前进,Xorbits Pandas 用并行算法重写了绝大部分 Pandas 函数,使得 Pandas 可以利用多核,多机器, 甚至多 GPU 来加速 DataFrame 的计算,在 1T 的数量级上,DataFrame 也可以轻松驾驭。下面是 TPC-H 1T 数据量上的测试结果。
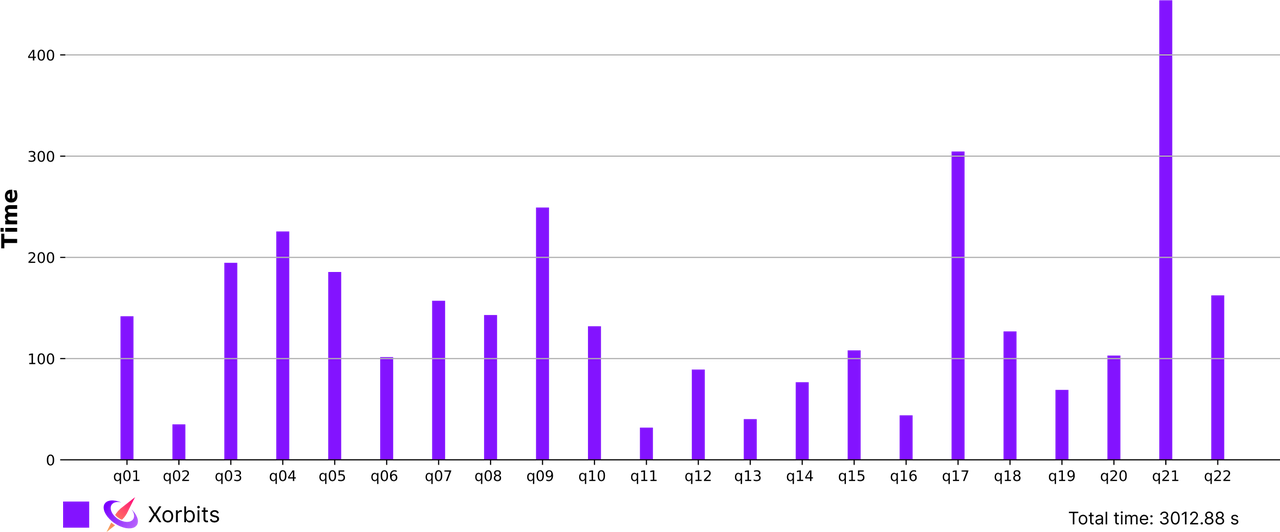
Pandas 2.0 给我们带来了非常大的信心,作为一个很早就引入 Arrow 作为存储格式的框架,Xorbits 能够更好地与 Pandas 配合, 我们也会一起参与建设一个更好的 DataFrame 生态。接下来,我们会尝试使用 Pandas 2.0 的 Arrow backend 加速 Xorbits 计算, 也会在下一篇文章中分享最新的结果。
总结
Pandas 2.0 是一个让人兴奋的更新,解决了许多 Pandas 经常被提起的问题,这篇文章主要介绍了 Arrow 的集成和 Copy-on-Write 的引入, 同时 Xorbits 等分布式 Pandas 的出现,也让整个 Pandas 生态愈发完整。

